Wirtschaftsinformatik (Bachelor-Studiengang): Rechnerarchitketur & Betriebssysteme (1. Semester)
Sie sind hier: Startseite › Wirtschaftsinformatik › Rechnerarchitektur/Betriebssysteme: Prozesse
BM / CM, Kurs vom 01.04.2002 - 30.09.2002
Prozesse
Die Geschwindigkeit der CPU und die der I/O-Geräte ist sehr unterschiedlich:
- 1 Befehl sei mit 10 Takten durchgeführt, d.h. bei einer Taktrate von 1 GHz ist ein Befehl nach 10 ns beendet.
- 1 Plattenzugriff liegt im günstigsten Fall bei 1 ms (real 3-4 ms, bei Laptop-Platten bei 12 ms).
Da 1 ms = 1.000.000 ns sind, heißt das, dass die CPU während eines Plattenzugriffs bei diesen Beispielzahlen ca. 100.000 Instruktionen ausführen kann.
Um die kostbare CPU-Zeit während der I/O-Wartezeit zu nutzen, sollte diese Wartezeit mit der Abarbeitung anderer Programme/Prozesse zugebracht werden. Das führt zum Konzept der Prozesse und der Umschaltung zwischen Prozessen.
Bevor dies erklärt werden kann, sind einige Vorarbeiten notwendig.
Durchführung von I/O-Vorgängen
Ein I/O-Vorgang wird durch Setzen von Geräteregistern gestartet. Seine Beendigung wird durch Abfragen eines bestimmten Geräteregisters, dem Status-Register, erkannt. Dort zeigt ein Bit - das Busy-Bit - an, ob der letzte Vorgang beendet ist.
- Polling = Befragung der CPU nach dem Status
- Busy Waiting = Ausschließliches Polling
Setzen der Geräteregister // Absetzen eines Kommandos
WHILE Busy-Bit = 1 DO
; // keine Operation
OD
Ergebnis auswerten
Das Lesen/Schreiben von einzelnen Worten bei Massenspeichern ist viel zu ineffizient: es werden daher immer Blöcke von mindestens 1 KB pro Vorgang verarbeitet.
Das Veranlassen eines I/O-Vorgangs wird auch als Absetzen eines I/O-Kommandos (Request) bezeichnet. Derartige Kommandos bestehen nicht immer aus dem Setzen eines Bits, sondern aus Mitteilen von kodierten Kommandos, z.B. bei ATAPI- oder SCSI-Geräten.
Die Programmteile im Kernel, die Zugriff auf die Geräte-Register haben, werden Treiber (Device Driver) genannt. In ihnen sind die speziellen Eigenschaften der Geräteregister versteckt.
Das Problem besteht nun darin, dass die I/O-Geräte um den Faktor mindestens 10.000 langsamer als die CPU sind, so dass die CPU mit dem Busy Waiting sehr viel Zeit vergeudet.
Idee:
Während des Wartens auf I/O arbeitet die CPU ein anderes Programm ab bis der I/O-Vorgang beendet ist; dann wendet sie sich wieder dem alten Prozess zu. Dazu ist aber ein Prozesswechsel notwendig.
Prozesswechsel mit resume()
Es wird nun eine gedachte (weil so nicht implementierbar) Operation
Namens resume() erfunden, die konzeptionell immer dann benutzt
wird, wenn klar ist, dass die CPU längere Zeit
warten muss.
resume(Neuer_Prozess) beschreibt den Ablauf beim
Prozesswechsel in einer Freistil-Notation:
Quelltext überspringen
resume(Prozess P) =
Wechsel in den Kernel-Modus
Rette die allgemeinen Register // aktueller Prozess
Rette Programm Counter, Status Register und Stack Pointer
// aktueller Prozess
Setze Memory Management Unit-Deskriptoren von P // neuer Prozess P
Stelle Programm Counter, Status Register und Stack Pointer
her // neuer Prozess P
Stelle allgemeine Register her // neuer Prozess P
Wechsel in den User-Modus
Prozesswechsel mit resume(p):
Beide Prozesse arbeiten im User-Mode
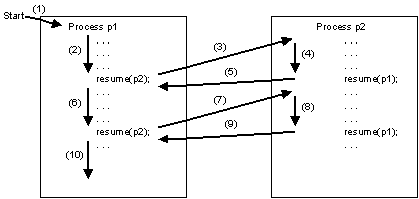
Bildbeschreibung "Prozesswechsel mit
resume": Erstens: Prozess p1 wird gestartet.
Zweitens: Prozess p1 wird teilweise ausgeführt.
Drittens: Prozess p2 wird aufgerufen. Viertens:
Prozess p2 wird teilweise ausgeführt.
Fünftens: Prozess p1 wird erneut aufgerufen.
Sechstens: Prozess p1 wird teilweise weiter
ausgeführt. Siebtens: Prozess p2 wird erneut
aufgerufen. Achtens: Prozess p2 wird bis zum Ende
ausgeführt. Neuntens: Prozess p1 wird ein letztes
Mal aufgerufen. Zehntens: Prozess p1 wird bis zum Ende
ausgeführt.
Die erste Hälfte des Ablaufs beim
resume() gehört zum alten, die zweite zum neuen
Prozess. Der eigentliche Wechsel besteht darin, dass nach dem
Retten des CPU-Inhalts mit dem Setzen
der MMU-Register (Virtueller
Speicher) begonnen wird.
In einer Tabelle im Kern sind die CPU-Inhalte mit den MMU-Deskriptoren jeweils für jeden Prozess getrennt abgelegt. Diese Tabelle wird meist Prozesstabelle oder Tasktabelle genannt.
Ein Eintrag in dieser Tabelle wird Prozessdeskriptor genannt. In diesem werden auch Register und MMU-Deskriptoren aufbewahrt.
Systemaufruf
Die Freistilnotation betrifft nur den Fall, dass ein Prozesswechsel aus einem laufenden Programm (Prozess) zu einem anderen laufenden Programm stattfinden soll.
Bei einem Systemaufruf ohne Prozesswechsel läuft der erste
Teil des resume() ab:
Quelltext überspringen
Syscall(Name, Parameter) =
Wechsel in den Kernel-Modus
Rette die allgemeinen Register // aktueller Prozess
Rette Programm Counter, Status Register und Stack Pointer
// aktueller Prozess
...
Führe den Syscall Name mit Parameter aus
...
Stelle Programm Counter, Status Register und Stack Pointer
her // aktueller Prozess
Stelle allgemeine Register her // aktueller Prozess
Wechsel in den User-Modus
Prozesswechsel innerhalb des Systemaufrufs:
Wenn nun ein Syscall
mit I/O,
z.B. Lesen von einer Floppy, durchgeführt wird, wird
der erste
Teil des Resume() durch den Syscall ausgeführt.
Der Prozesswechsel findet dann in dem Code des Systemaufrufs
statt, wobei die Operation continue(Prozess) die 2.
Hälfte des resume() symbolisiert:
Quelltext überspringen
... // Syscall ausführen
Setzen der Geräteregister // Absetzen eines Kommandos
WHILE Busy-Bit = 1 DO
Continue(Prozess) // Central Processing Unit abgeben
OD
... // Syscall beenden
continue(Prozess)
continue(Prozess) ist die 2. Hälfte des
resume(), die mit dem Laden des MMU-Desktriptor
beginnt.
Der Parameter Prozess ist eine Identifikation - in der Regel eine Nummer: Prozess-ID - des Prozesses, der fortgeführt werden soll.
Nach Beendigung von continue(Prozess P) wird der
Prozess P direkt nach dessen letzten continue()
weiterausgeführt.
Wechselseitiges Aktivieren sieht dann so wie in der nachfolgenden Grafik aus.
Doch es gibt ein Problem: Der Prozess, der zu warten beginnt, muss wissen, welche Prozesse existieren und welcher von diesen weiter arbeiten soll.
Daher wird in diesen Fällen zu einem Prozess Namens Scheduler gewechselt, der den Prozesswechsel übernimmt.
Prozesswechsel innerhalb von Systemaufrufen:
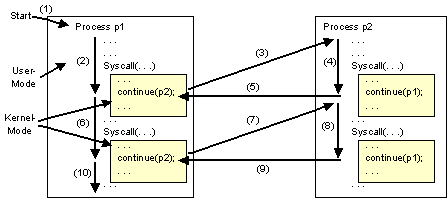
Bildbeschreibung "Prozesswechsel innerhalb von Systemaufrufen": Abbildung der vorangehend beschriebenen Vorgehensweise.
Scheduler
Der Scheduler ist ein Prozess bzw. eine Routine innerhalb des Kernel, die für folgende Aufgaben zuständig ist:
- Mitschreiben, welche Prozesse existieren (in der Prozesstabelle)
- Vermerken, welcher Prozess zu welchem Anteil die CPU schon bekommen hat
- Vermerken des Prozesszustandes:
Running: Prozess hat gerade die CPUReady: Prozess wartet auf CPUWaiting: Prozess wartet auf Beendigung von I/OSleeping: Prozess benötigt später die CPU
- Ändern des Prozesszustands entsprechend der Situation
- Zuteilen der CPU den nächsten Prozess
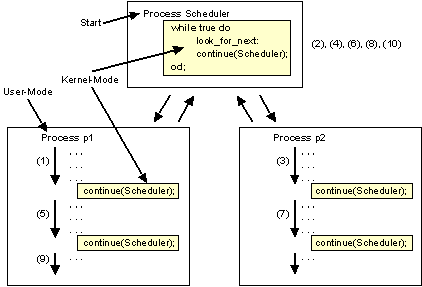
Bildbeschreibung "Scheduler": Anstelle des direkten Wechsels zwischen Prozess 1 und Prozess 2 ist jedesmal der Scheduler zwischengelagert.
Verkürzte Version: das continue(Scheduler) ist
Teil eines Syscalls.
Der Scheduler selbst arbeitet
permanent im Kernel-Modus.
Anstatt in einer Endlosschleife die (kostbare) CPU-Zeit
zu vertun, gibt der Prozess freiwillig die CPU ab, um
sie später erneut zum nächsten Polling wieder zu erhalten:
Quelltext überspringen
Process p1
...
Setzen der Geräte-Register
Starten des Input/Output-Vorgangs
WHILE Busy Bit = 1 DO
continue(Scheduler)
OD
...
Es ist immer noch das Polling (Nachsehen, ob der I/O-Vorgang beendet ist) notwendig. Dies ist zwar schon reduziert, aber noch vorhanden.
Eine Endlosschleife eines einzigen Prozesses bringt das gesamte System zum Absturz, da nur mit der Beendigung des Ganzen dieser eine Prozess beendet werden kann. Besser ist, dass nur der Prozess mit der Endlosschleife getrennt von den übrigen beendet wird.
Unterbrechungen (Interrupts)
Wenn ein I/O-Gerät seine Operation beendet hat, sendet es über den Bus ein Signal, das von der CPU als Unterbrechung (Interrupt) behandelt wird.
Empfängt die CPU dieses Signal, so passiert folgendes:
- Die Ausführung der aktuellen Instruktion wird beendet.
- Anstatt die nächste Instruktion auszuführen, wird die
erste Hälfte des
resume()ausgeführt.
Die Behandlung im Kernel besteht in der Ausführung einer für diesen Interrupt speziellen Routine, dem Interrupt-Handler (Unterbrechungsbehandler). Dieser tut folgendes:
- Feststellen, welches Gerät den Interrupt signalisierte.
- In der Prozesstabelle alle Prozesse, die auf diesen Interrupt warteten, in den Zustand
Readyzu bringen.
Ablauf beim Interrupt:
- Version I:
In dieser Version wird das aktuell laufende Programm lediglich unterbrochen und nach Bearbeiten des Prozesstabelle wieder fortgeführt.Dies hat den Nachteil, dass Prozesse, die auf den Interruptlange gewartet haben, noch weiter warten müssen.
Interrupt Handler =
Wechsel in den Kernel-Modus
Rette die allgemeinen Register
Rette Programm Counter, Status Register und Stack Pointer
Bestimme signalisierendes Gerät
Setze wartende Prozesse auf Ready
Stelle Programm Counter, Status Register und Stack Pointer her // alte Werte
Stelle allgemeine Register her // alte Werte
Wechsel in den User-Modus // Prozess weiter ausführen - Version II:
In dieser 2. Version wird direkt nach dem Bearbeiten der Prozesstabelle zum Scheduler gewechselt, der dann entscheidet, mit welchem Prozess es weiter geht.Der Scheduler durchsucht bei jedem seiner Aufrufe die gesamte Prozesstabelle nach Prozessen im Zustand "
Ready" bzw. "Running", um einen von diesen auszuwählen. Alle anderen Prozesse werden von ihm ignoriert.Interrupt Handler =
Wechsel in den Kernel-Modus
Rette die allgemeinen Register
Rette Programm Counter, Status Register und Stack Pointer
Bestimme signalisierendes Gerät
Setze wartende Prozesse auf Ready
continue(Scheduler) // Zum Scheduler wechseln
Die beiden Behandlungsmöglichkeiten:
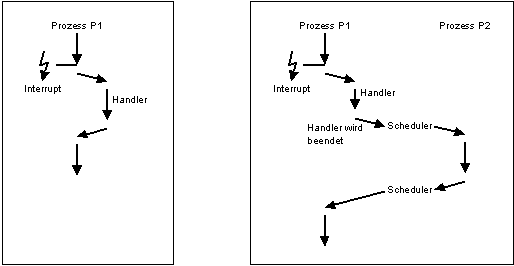
Bildbeschreibung "Behandlungsmöglichkeiten": Variante 1 = Prozess, Interrupt, Handler, Prozess. Variante 2 = Prozess, Interrupt, Handler, Handler wird beendet, Scheduler ... Prozess.
Warten auf I/O mit Interrupts:
Der Prozess setzt sich freiwillig auf eine Warteliste, indem er in
den Zustand "Waiting" geht. Ein I/O-Deskriptor
beschreibt das Gerät bzw.
den Vorgang, auf den der Prozess wartet.
Wenn der Interrupt-Handler
dieses Geräts aktiviert wird, werden alle mit dem dessen I/O-Deskriptor
wartenden Prozesse in den Status "Running" gesetzt.
Process p1
...
Setzen der Geräte-Register
Starten des Input/Output-Vorgangs
wait(Input/Output-Deskriptor);
...
...
PROC wait(Input/Output-Deskriptor)
Setze Prozess Status("Waiting");
Trage Input/Output-Deskriptor in Tabelle;
continue(Scheduler);
Durch den Mechanismus des Interrupt entfällt vollkommen das Polling und damit auch das Busy Waiting.
Ein auf I/O wartender Prozess wird erst dann aktiviert, wenn der I/O-Vorgang beendet ist. Besser geht es nicht mehr.
Was passiert, wenn alle Prozesse auf I/O warten?
Ganz einfach: dann findet der Scheduler keinen Prozess, den er aktivieren kann und durchsucht in einer Endlosschleife seine Prozesstabelle bis er unterbrochen wird.
Dieser Interrupt-Handler
setzt dann einen der Prozesse auf "Ready" und kehrt in der
1. Version einfach zurück; dann findet der Scheduler, was er suchte. In der 2. Version
würde er ja sowieso aktiviert werden ...
Time Sharing Verfahren
Mit den vorgestellten Mechanismen lassen sich alle Nachteile bis auf die "Ungerechtigkeiten" bei der CPU-Vergabe sowie auf den Fall der Endlosschleifen beseitigen. Dies wird durch einen Timer gelöst.
Ein Timer ist ein spezielles I/O-Gerät, das nach einer eingestellten Zeit bzw. in zyklischen Abständen einen speziellen Interrupt sendet. Dieser wird immer mit dem Aktivieren des Scheduler aus dem Handler heraus behandelt.
Die Dauer zwischen zwei Timer-Interrupts wird Zeitscheibe genannt.
Nach Ablauf einer Zeitscheibe kann damit der Scheduler die CPU an einen anderen Prozess geben, unabhängig davon, ob ein I/O-Vorgang erfolgt ist.
Scheduling-Verfahren
Zyklisches FIFO (First In First Out) oder Round-Robin: Den Prozessen wird zirkulär hintereinander die CPU gegeben, wobei die Zeitscheiben in der Regel gleichlang sind.
High Priority First:
- Alle Prozesse haben eine Priorität.
- Prozesse mit der höchsten Priorität werden bevorzugt.
- Prozesse mit niedriger Priorität bekommen nur dann die CPU, wenn höherwertige Prozesse im Status "Waiting" oder nicht vorhanden sind.
Mischform "Priorisiertes Round-Robin":
![]()
Bildbeschreibung "Round Robin": Den Prozessen wird zirkulär hintereinander die CPU gegeben, wobei die Zeitscheiben in der Regel gleichlang sind.
Round Robin mit Prioritätsklassen:
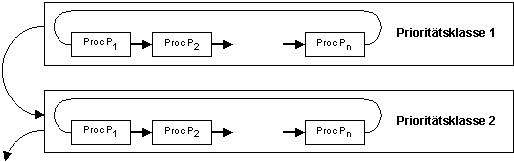
Bildbeschreibung "Round Robin": Den Prozessen wird zirkulär hintereinander die CPU gegeben, wobei die Zeitscheiben in der Regel gleichlang sind. Einzelne Prozesse werden jedoch zu Prioritätsklassen zusammengefasst. Innerhalb dieser Klassenbildung erfolgt dann die zyklische Abarbeitung. Erst Prozesse der Priorität 1, dann die Prozesse der Priorität 2.
Scheduling mit Swapping
Bisher wurde nur "normales" I/O behandelt. Beim Swapping wird auch I/O gemacht, so dass dies in analoger Weise behandelt werden kann:
- Bei jedem Swap-Vorgang
(Swap-In und Swap-Out) wird der behandelte Prozess
entsprechend in den Status "
Swap-In" bzw. "Swap-Out" versetzt. - Diese beiden Wartezustände bedeuten, dass der Prozess auf die Beendigung eines I/O-Vorgangs auf dem Swap-Gerät wartet.
- Bis auf dass Swap-Vorgänge höher priorisiert werden, liegt kein Unterschied zum "normalen" I/O vor.
- Die Prozesse behandeln ihre eigenen Swap-In und Swap-Out-Vorgänge wie ihre sonstigen I/O-Vorgänge selbst.
Swapping impliziert noch weitere Bedingungen:
- Wenn ein spezieller Prozess für das Swapping zuständig ist, so darf dieser auf keinen Fall heraus "geswapped" werden - warum wohl?
- Der Swapping-Prozess sollte auch eine sehr hohe Priorität haben, d.h. sich nicht nach einer Zeitscheibe bzw. nach einem I/O-Start nach der Round-Robin-Strategie hinten anstellen.
Wenn der Scheduler sich für einen Prozess entschieden hat, der in diesem Moment heraus "geswappt" ist, muss er das herein-swappen veranlassen, was zu einem I/O-Vorgang führt. Dies bedeutet, dass vielleicht ein anderer Prozess, der später die CPU bekommen soll, aber schon im RAM liegt, die CPU während der Wartezeit dieses Swappings erhält, d.h. er bekommt etwas CPU-Priorität geschenkt.
Ein resume() kann immer nur zu einem Prozess, der
im RAM liegt, erfolgen.
Ist der andere Prozess, zu dem gewechselt werden soll, nicht im RAM, so muss er vorher geholt werden.
Bei der Entscheidung für ein Swap-In muss manchmal entschieden werden, welche von den in RAM liegenden Prozessen vorher heraus "geswappt" werden sollen. Zu diesen Prozessen darf natürlich nicht gewechselt werden, um die Wartezeit des Swapping zu überbrücken.