Wirtschaftsinformatik (Bachelor-Studiengang): Betriebliche Datenmodellierung und Datenbankanwendungen (2. Semester)
Sie sind hier: Startseite › Wirtschaftsinformatik › Betriebliche Datenmodellierung und Datenbankanwendungen
IC / CM, Kurs vom 01.10.2002 - 31.03.2003
Einführung
Information als geschäftsentscheidender Faktor
- Beispiele
- Banken
- Versicherungen
- Versandhandel
- Krankenhäuser
- Ämter
- Unternehmen allgemein
- Korrektheit
- Verfügbarkeit
- Daten / Informationen
Informationsinfrastruktur
- Klassische Infrastrukturen
- Straßennetz
- Wasserversorgung
- Telefon
- Eigenschaften
- Langlebigkeit
- Partielle Erneuerung
- Koexistenz von Alt und Neu
- Ursachen für partielle Erneuerung
- Technischer Fortschritt
- Unternehmenswachstum
- Strategiewechsel bei der Geschäftsdurchführung
- Unternehmensübernahmen, -zusammenschlüsse
- Probleme von betrieblichen Informationsinfrastrukturen
- Redundanz
- Inkonsistenz
Mengen, Produkte, Relationen
- Mengen
- Kartesisches Produkt
- Menge von Paaren für zwei Mengen M und N
- M × N = {(m,n) | m ∈ M, n ∈ N}
- Relationen
- Teilmenge des karthesischen Produkts
- R ⊆ M × N
- Linkstotal: ∀ m ∈ M ∃ n ∈ N: (m,n) ∈ R
- Rechtstotal: ∀ n ∈ N ∃ m ∈ M: (m,n) ∈ R
- Rechtseindeutig: ∀ n1, n2 ∈ N: (m,n1) ∈ R, (m,n2) ∈ R ⇒ n1 = n2
- Linkseindeutig: ∀ m1, m2 ∈ M: (m1,n) ∈ R, (m2,n) ∈ R ⇒ m1 = m2
Linkstotal: alle Elemente einer linken Menge (M) haben eine Beziehung zu Elementen der rechten Menge (N).
Rechtstotal: alle Elemente einer rechten Menge (N) haben eine Beziehung zu Elementen der linken Menge (M).
Rechtseindeutig: einem Element der linken Menge dürfen nicht zwei Elemente der rechten Seite zugeordnet sein.
Linkseindeutig: einem Element der rechten Menge dürfen nicht zwei Elemente der linken Seite zugeordnet sein.
Funktionen (spezielle Relationen):
- Partielle Funktion: Rechtseindeutig
- Partielle injektive Funktion: Rechtseindeutig, Linkseindeutig
- Partielle surjektive Funktion: Rechtseindeutig, Rechtstotal
- Partielle bijektive Funktion: Rechtseindeutig, Linkseindeutig, Rechtstotal
- Totale Funktion: Rechtseindeutig, Linkstotal
- Totale injektive Funktion: Rechtseindeutig, Linkstotal, Linkseindeutig
- Totale surjektive Funktion: Rechtseindeutig, Linkstotal, Rechtstotal
- Totale bijektive Funktion: Rechtseindeutig, Linkstotal, Linkseindeutig, Rechtstotal
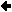
![]()
Relationenmodell
Zentrales Element: Tabelle = Tabellenstruktur + Tabelleninhalt
Bildbeschreibung "Relationenmodell": Tabellenname = Student. Spaltenname (= Attributname = Feldname) = Matrikelnummer, Name, Vorname. Schlüsselattribut (unterstrichen) = Matrikelnummer. In jeder Zeile der grafisch dargestellten Tabelle steht ein Datensatz, auch Tupel genannt. Beispiel 1: 93129, Meier, Hans (Matrikelnummer, Name, Vorname).
Spaltentyp = Attributtyp = Felddatentyp = Domain = Wertebereich
Mathematische Interpretation
Tabellenstruktur (Relationenschema):
- Tabellenname + Attributnamen + Wertebereiche der Attribute
- Schreibweise: R(A1, ..., An)
Tabelleninhalt:
- Menge der Datensätze + Zuordnung der Datenwerte
Menge der Datensätze:
- Schreibweise: D = { d1, ..., dk }
- D entspricht der Menge der Speicheradressen der Datensätze
Zuordnung der Datenwerte:
- Partielle Funktion
- Schreibweise: A: D -> Wertebereich(A)
- A ist ein Attributname aus dem Relationenschema
- Ordnet jedem Speicherplatz den darin gespeicherten Wert zu
- Kann Nullwerte handhaben
Beispiel Studenten:
- Relationenschema:
Student(MatrNr, Name, Vorname) - Datensätze:
D = { d1, ..., d4 } Wertebereich(MatrNr) = VARCHAR(15)Wertebereich(Name) = VARCHAR(200)Wertebereich(Vorname) = VARCHAR(200)MatrNr = { (d1,93129), (d2,92187), (d3,96089), (d4,98017) }Name = { (d1,"Meier"), (d2,"Müller"), (d3,"Schulze"), (d4,"Lehmann") }Vorname = { (d1,"Hans"), (d2,"Frank"), (d4,"Simone") }
Darstellungsarten für Relationenschemata
Tabellarische Darstellung:
![]()
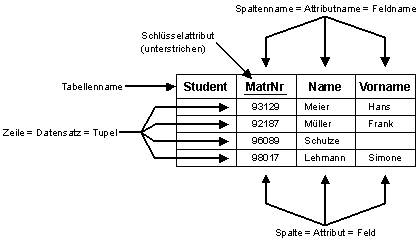
Bildbeschreibung "Tabellarische Darstellung": Spalte 1: Student (Tabellenname), Spalte 2: Matrikelnummer, Spalte 3: Name, Spalte 4: Vorname.
Mathematische Darstellung:
![]()
Bildbeschreibung "Mathematische Darstellung": Student(Matrikelnummer, Name, Vorname)
Graphische Darstellung:
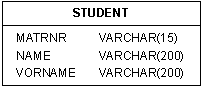
Bildbeschreibung "Graphische Darstellung": Darstellung über ein Rechteck. Diese beinhaltet: Titel = Student, Attribute = Matrikelnummer als Varchar(15), Name als Varchar(200) und Vorname als Varchar(200).
Datenbank-Skript:
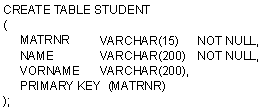
Bildbeschreibung "Datenbank-Skript":
Create table Student {...}. Zwischen den Klammern stehen dann die
Angaben der graphischen Darstellung sowie die Definition des
Primärschlüssels.
Schlüssel
Projektion auf Spalten:
Gegeben:
- Ein Relationenschema R(A1, ..., An)
- Ein Menge von Datensätzen D = { d1, ..., dk }
- Ein Datensatz di ∈ D
- Eine Liste L mit Attributen aus dem Relationenschema R
Projektion der Attribute aus L auf den Datensatz di:
- Schreibweise: di[L]
Beispiel:
L = { Name, Vorname }
d2[L] = d2[Name, Vorname] =
("Müller", "Frank")
Schlüssel:
- Attribute, die jeden Datensatz einer Tabelle eindeutig identifizieren
- Definition:
∀d1,d2∈D: d1[L] = d2[L] ⇒ d1 = d2 - Ein Primarschlüssel wird aus der Menge der Schlüssel ausgewahlt
- Besteht ein Schlüssel aus mehr als einem Attribut, so ist er ein zusammengesetzter Schlüssel
- Beispiel:
L = { MatrNr }
Fremdschlüssel
Ein Fremdschlüssel identifiziert Zeilen in einer anderen (fremden) Tabelle.
Gegeben R(A1, ..., An) und V(B1, ..., Bk): Ist ein Ai ein Fremdschlüssel in R, der auf den Primärschlüssel B1 in V verweist, so müssen Ai und B1 den gleichen Wertebereich haben und alle Werte in der Spalte Ai müssen in der Spalte B1 vorkommen (referenzielle Integrität).
Ist der Primärschlüssel zusammengesetzt, so auch der Fremdschlüssel.
Beispiel: SG ist Fremdschlüssel im Relationenschema Student und verweist auf das Attribut KurzBez im Relationenschema Studiengang
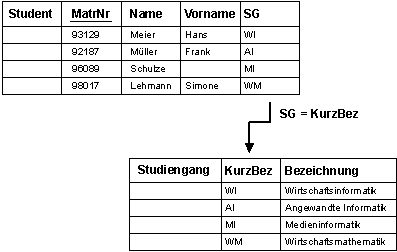
Bildbeschreibung "Fremdschlüssel": Die Tabelle wird ergänzt um die Spalte Studiengang, kurz: SG. Dieses Attribut verweist auf eine zweite Tabelle, die Tabelle Studiengang. In dieser stehen zeilenweise die unterschiedlichen Studiengänge mit einer zugehörigen Kurzbezeichnung. Diese Kurzbezeichnung ist in der zweiten Tabelle Primärschlüssel, in der ersten Tabelle Fremdschlüssel.
Funktionale Abhängigkeiten und Schlüssel
Schlüssel:
Identifizieren eindeutig die Datensätze (Zeilen) einer Tabelle.
Nicht-Schlüssel-Attribute:
Sind die Attribute, die nicht zum Schlüssel gehören.
Funktionale Abhängigkeit:
Ein Attribut B ist funktional von einem Attribut A
abhängig, wenn die Werte von B durch die Werte von
A bestimmt werden.
Alle Attribute sind funktional vom Schlüssel abhängig.
Volle funktionale Abhängigkeit vom Schlüssel:
Nicht-Schlüssel-Attribute sind voll funktional abhängig vom Schlüssel, wenn sie nicht schon von einem Teil des Schlüssels funktional abhängig sind.
Erste Normalform
Definition: Alle Attribute sind atomar, d.h. sie dürfen selbst keine Tabellen sein.
Gegenbeispiel:
Bildbeschreibung "Gegenbeispiel Erste Normalform": In der ersten Normalform dürfen Attribute selbst keine Tabellen sein!
Zweite Normalform
Definition:
- Ist in erster Normalform.
- Alle Nicht-Schlüssel-Attribute sind voll funktional abhängig vom Schlüssel.
Erläuterung:
- Zusammenfassung aller zusammengehörenden Fakten
- Vermeidung von Einfüge-, Lösch-, Änderungsanomalien
Gegenbeispiel:

Bildbeschreibung "Gegenbeispiel Zweite Normalform": In der zweiten Normalform sind alle Nicht-Schlüssel-Attribute voll funktional abhängig vom Schlüssel.
Dritte Normalform
Definition:
- Ist in zweiter Normalform.
- Es gibt keine funktionale Abhängigkeit zwischen Nicht-Schlüssel-Attributen.
Erläuterung:
- Keine transitiven Abhängigkeiten
- Trennung nicht zusammengehörender Fakten
- Vermeidung von Einfüge-, Lösch-, Änderungsanomalien
Gegenbeispiel:

Bildbeschreibung "Gegenbeispiel Dritte Normalform": In de dritten Normalform gibt es keine funktionale Abhängigkeit zwischen Nicht-Schlüssel-Attributen.
![]()
Modellierung
Zweckgebundene Beschreibung eines Gegenstandsbereichs (Realität) in einer formalisierten Form.
Datenmodellierung:
Modellierung von Informationsstrukturen.
(Zweck: z.B. Verstehen der
Informationsstrukturen, Implementierung in Datenbanksystemen)
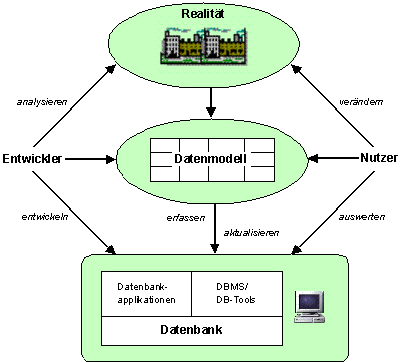
Bildbeschreibung "Modellierung": Die Realität wird in einem Datenmodell beschrieben und in einer Datenbank abgebildet.
Entity Relationship-Modellierung
- Kurzform: ER-Modellierung
- Modellierung von
- Dingen
- Attributen (von Dingen)
- Beziehungen (zwischen Dingen)
- Modell / Schema
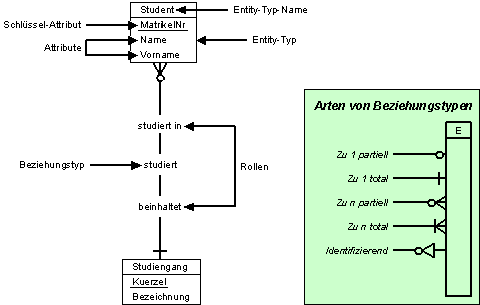
Bildbeschreibung "Konzepte": Zwei Entities. Erstens: Entity-Typ-Name = Student, Entity-Typ beinhaltet das Schlüssel-Attribut Matrikelnummer sowie die Attribute Name und Vorname; Rolle = studiert in. Zweitens: Entity-Typ-Name = Studiengang, Entity-Typ beinhaltet das Schlüssel-Attribut Kürzel sowie das Attribut Bezeichnung; Rolle = beinhaltet. Der Beziehungstyp zwischen den beiden Entities lautet studiert.
Generalisierung:
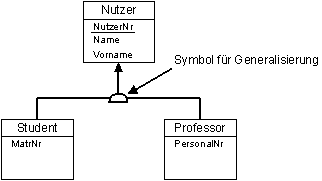
Bildbeschreibung "Generalisierung": Ein Nutzer hat die Attribute Nutzer-Nummer, Name und Vorname. Es gibt zwei Arten von Nutzern: Erstens den Studenten und zweitens den Professor. Der Student hat das zusätzliche Attribut Matrikelnummer, der Professor das Attribut Personalnummer.
![]()
Relationenalgebra
Relationenmodell
Die Grundlage des Relationenmodells bilden Tabellenstrukturen mit ihren Spalten und Zeilen.
Relationenschema:
Ein Relationenschema R(A1, ..., An) ist durch einen Relationennamen R und eine Menge von Attributen {A1, ..., An} gegeben. Attribute werden auch Spalten oder Felder genannt. Jedem Attribut Ai ist ein Wertebereich dom(Ai) zugeordnet, wobei Wertebereiche natürliche Zahlen, Zeichenketten, Datumsangaben usw. sein können.
Tabellen:
Eine Tabelle T zu einem Relationenschema R(A1, ..., An) ist durch eine Menge von Zeilen {z1, ..., zk} und eine Menge von partiellen Attributfunktionen Ai : T → dom(Ai) gegeben für alle i ∈ 1, ..., n. Jede Attributfunktion Ai : T → dom(Ai) ordnet jeder Zeile zj der Tabelle T den Wert des Attributs in dieser Zeile zu. Ist die Attributfunktion für eine Zeile nicht definiert, so liegt für das entsprechende Attribut kein Wert vor. Das entspricht einem Nullwert in relationalen Datenbanksystemen.
Relationenoperatoren
Im folgenden werden die Operatoren Projektion, Selektion und Produkt definiert. Die Operatoren werden sowohl auf Relationenschemata angewendet und ergeben dann ein Ergebnisschema als auch auf entsprechende Tabellen und ergeben dann eine Ergebnistabelle.
- Das Ergebnisschema wird immer mit Rerg bezeichnet.
- Die Ergebnistabelle wird immer mit Terg bezeichnet.
Des weiteren werden folgende Objekte definiert:
- Zwei Relationenschemata R(A1, ..., An) und S(B1, ..., Bm)
- Eine Tabelle T = {z1, ..., zk} zum Schema R
- Eine Tabelle T' = {y1, ..., yl} zum Schema S
- Eine Zeile z aus Tabelle T und eine Zeile y aus Tabelle T'
- Eine Teilmenge {A1*, ..., Ap*} der Attribute aus {A1, ..., An}
Projektion:
Die Projektion von R auf die Attribute A1*, ... Ap* wird R[A1*, ... Ap*] geschrieben und ergibt das Relationenschema Rerg(A1*, ... Ap*). Die Tabelle Terg ist gleich T, d.h. die Zeilen und die in der Projektion enthaltenen Attribute bleiben unverändert.
Selektion:
Die Selektion von R bezüglich einer Bedingung C wird R<C> geschrieben und ergibt das Relationenschema Rerg(A1, ... An). Das Ergebnisschema enthält dieselben Attribute wie das Ausgangsschema. Die Tabelle Terg enthält alle Zeilen aus T, die die Bedingung C erfüllen. Die Attribute bleiben unverändert.
Der Ausdruck für die Bedingung C kann entsprechend der folgenden Grammatik gebildet werden. Die Symbole der Grammatik bedeuten:
- Links von dem Gleichheitszeichen steht die zu definierende syntaktische Einheit
- Rechts davon steht die Definition
- Das Symbol | bedeutet oder
- Runde Klammern dienen zur Zusammenfassung von Teilausdrücken
- Symbole in Kursivschrift sind Literale, d.h. stehen für sich selbst
Produkt:
Das Produkt von R und S wird R,S geschrieben und ergibt das Relationenschema Rerg(R.A1, ..., R.An, S.B1, ..., S.Bm). Die Tabelle Terg ist das kartesische Produkt von T und T'. Die Attribute berechnen sich wie folgt: Sei X ein Attribut aus Rerg und x = (z,y) eine Zeile aus Terg.
![]()
Bildbeschreibung "Produkt": Formel. X(x) wird abgebildet durch Ai(z) falls X = R.Ai und Bj(y) falls X = S.Bj.
Der Schemaname R oder S kann vor dem Attribut weggelassen werden, wenn der Attributname im Ergebnisschema eindeutig ist.
| Schreibweise | Ergebnisschema | Ergebnistabelle | |
|---|---|---|---|
| Projektion | R[A1*, ... Ap*] | Rerg(A1*, ... Ap*) | Terg = T |
| Selektion | R<C> | Rerg(A1, ... An) | Terg ⊆ T |
| Produkt | R,S | Rerg(R.A1, ..., R.An, S.B1, ..., S.Bm) | Terg = T × T' |
Relationenschemata können mit dem Symbol → umbenannt werden. Z.B. werden in dem Produkt R → R1, S → R2 die Relationenschemata R und S in R1 bzw. R2 umbenannt. Umbenennungen können auch auf Attribute angewendet werden. Sie sind notwendig, um eindeutige Namen zu erzeugen.
Spaltenberechnungen:
Die Ergebnisspalten bei der Anwendung von Relationenoperatoren ergeben sich immer direkt aus den Spalten der zugrundeliegenden Relationenschemata. Um innerhalb von Spalten Berechnungen durchführen zu können, müssen Spaltennamen durch Spaltenausdrücke ergänzt werden.
Spaltenausdrücke werden entsprechend der folgenden Grammatik gebildet und können überall dort stehen, wo auch Attribute erlaubt sind.