Wirtschaftsinformatik (Bachelor-Studiengang): Grundlagen der Kommunikationstechnik (4. Semester)
Sie sind hier: Startseite › Wirtschaftsinformatik › Grundlagen der Kommunikationstechnologie: Schnittstellen / Übergabeformate (Architektur)
HH / CM, Kurs vom 01.10.2003 - 31.03.2004
Client Server Architektur
Interaktionsmuster in der IT
- Kooperation
Mehrere Prozesse arbeiten auf einem Datenbestand - Kommunikation
Ein Prozess sendet Daten an einen anderen Prozess
Client Server Architektur: Definition
Spezielle Form verteilter Systemarchitektur, unterteilt in:- Server: dienst-erbringend
- Client: dienst-anfordernd
Oft:
- Server zentral und passiv,
- Client aktiv
Client Server Architektur: Grundstruktur
- Client (z.B. Web-Browser)
- Schnittstellen
- Connective Technologies (z.B. TCP/IP mit Router, Hub)
- Schnittstellen
- Server (z.B. Web-Server mit Datenbank)
Der Begriff der "Middleware"
Als Middleware wird eine Software-Schicht zwischen (Netzwerk-) Betriebssystem und Applikationsebene bezeichnet.
![]()
Kommunikation in Rechnernetzen
Aufgaben von Kommunikationssystemen
- Personenbezogene Kommunikation
- klassisches Beispiel: Telefonie, heute digital
- neuere Dienste: Fax, Natel, electronic Mail, video-on-demand
- Computerkommunikation als Träger (Medium) personenbezogener Kommunikation
- Computernetze und verteilte Systeme (computerbezogene
Kommunikation)
- Computerkommunikation dient dem internen Funktionieren von Rechnerverbünden
- Beispiel: Fileserver, Printserver, Datenbank-Server
- Integration
- beliebige Übergänge: Datenübertragung via Telefon, Telefonie via Computernetze
- keinen Unterschied zwischen Datenverarbeitung und Computerkommunikation
- keinen Unterschied bei der Bearbeitung von EDV-Daten, Sprache und Video
Herausforderung Computerkommunikation
Computerkommunikation als komplexe Planungs- und Implementierungsaufgabe
- Verschiedenste Anwendungen und Anforderungen:
- vom einfachen Terminal bis zur Multimedia-Workstation mit Video und Audio
- Implementierung von Kommunikations-Software für den PC und den Grossrechner
- Sehr viele involvierte Parteien:
- Kommunikations-Software wird von verschiedenen Leuten implementiert
- diese Versionen müssen untereinander kompatibel sein
- und richtig konfiguriert sein
- und unter allen Umständen funktionieren, auch wenn eine Leitung unterbrochen,
- ein entfernter Rechner abgestellt, ein weiterer Rechner ins Netz dazugeschaltet wird.
- Kommunikations-Software ist erfahrungsgemäss robuster
als gewöhnliche Software:
- Fehler werden sehr schnell sichtbar (sind aber deswegen nicht leichter zu beheben)
Fragestellungen:
- Zum Inhalt
- Welche Dienste sollen durch ein Kommunikationssystem unterstützt werden?
- Welche Dienstqualität ist notwendig?
- Zur Anwendung
- Wie wird ein Kommunikationsdienst dem Benutzer angeboten?
- Wie kann der Einsatz von Kommunikationsdiensten automatisiert werden?
- Zur Technologie
- Welche Materialien stehen zur Datenübertragung zur Verfügung?
- Wie kann ein Dienst überhaupt erbracht werden?
- Wie wird die entsprechende Kommunikations-Software geschrieben?
- Wie wird die Kompatibilität mit anderen Herstellern erreicht?
- Wie muss ein Dienst verwaltet und gesteuert werden?
Architekturen für Computerkommunikation
Computerkommunikation verlangt eine perfekte Kooperation!
- Kommunikations-Software wird mit Kommunikations-Software
gekoppelt (und nicht mit einem gutmütigen und fehlertoleranten
menschlichen Benutzer).
Beispiel: Gegenseitiges Anrufen mit dem Telefon
Im Falle von programmierter Wahlwiederholung kann folgendes passieren:
- zufällig versuchen beide Seiten, gleichzeitig die Gegenseite anzurufen
- da besetzt, warten beide Seiten eine vorprogrammierte Zeit
- der nächste Versuch wird wieder scheitern, da wieder Gleichzeitigkeit
Der Anruf wird nie zustande kommen, obwohl beide Seiten es möchten.
Bedarf für eine Kommunikationsarchitektur:
- Eine Kommunikationsarchitektur gibt an, wie das Problem Computerkommunikation in kleine, handhabbare Teilprobleme zu zerlegen ist.
Kommunikationsmodelle
Shannons Kommunikationsmodell (1949):
- Shannon: theoretische Untersuchungen über Verschlüsselung und Fehlerkorrektur
- Obwohl ein technisches Modell, wird es selbst in den Literaturwissenschaften zitiert.
- Zwei Formen von Information: Meldung und Signal
- Zwei zentrale Aktivitäten:
- Codierung der Meldung in ein Signal
- Decodierung des Signals, um die Meldung wieder herzustellen
- Gemeinsamer Code-Vorrat nötig auf Sender- und Empfängerseite
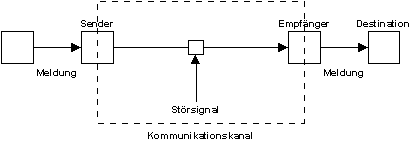
Bildbeschreibung "Shannons Kommunikationsmodell": Meldung des Senders wird codiert als Signal an den Empfänger geschickt. Dieser decodiert das Signal, um die ursprüngliche Meldung zu erhalten.
Die sechs Stufen der Kommunikation:
- Generierung (Musik, Stimmen, Bilder)
- Darstellung/Beschreibung (elektrisch, visuell)
- Kodierung
- Übertragung/Übermittlung
- Dekodierung
- Zusammensetzung
Spezielles Kommunikationsmodell für Computer:
- Anpassung I: Meldungen liegen in digitaler Form vor
- Anpassung II: Es existiert ein zweiter Kommunikationskanal für Rückmeldungen
- Anpassung III: Definition eines Protokolles, das festlegt, was für Meldungen in welcher Reihenfolge ausgetauscht werden
- Anpassung IV: Rekursive Struktur ein protokoll-erweiterter Kanal kann selbst als (virtueller) Kanal verwendet werden.
- Damit können Abstraktionsebenen für Computerkommunikation gebildet werden
- z.B. elektrisches Signal bit Zeichen Datenblock Dokument
- Jede Ebene hat ihr eigenes Protokoll (Codierung)
Notwendigkeit der Standardisierung:
Siehe das Modell von Shannon: Empfänger und Sender müssen einen gemeinsamen Code-Vorrat besitzen.
Die erste Entwicklung (1960-1970):
- jeder Computerhersteller entwickelte seine Protokolle
- keine direkte Kommunikation möglich zwischen Computern unterschiedlicher Hersteller
- bzw. die (geheimen) Protokolle der Konkurrenz müssten auch implementiert werden
- Implementierungsaufwand wächst quadratisch mit der Anzahl Teilnehmer
Deshalb: einen herstellerneutralen Satz von Protokollen definieren (analog der Standardisierung im technischen Bereich: Masseinheiten, Stahlqualitäten)
Heute sind zwei große Schulen "übriggeblieben" (neben herstellerspezifischem):
- das OSI-Referenzmodell (OSI = Open Systems Interconnection) der ISO
- die DoD-Protokollsuite (Department of Defense), bzw. das Internet
Offene Systeme
Wörtliche Interpretation von open systems:
Offene Systeme sind bereit, mit allen zu kommunizieren.
Definition offener Systeme:
Bedingung ist eine offene Spezifikation, d.h.- Inhalt öffentlich zugänglich (Zugang)
- durch Konsens erzielt (Verfahren)
- in mehreren Umgebungen implementierbar (Umsetzbarkeit)
Eigenschaften offener Systeme:
- Interoperabilität
- zwischen verschiedenen Implementierungen der gleichen Spezifikation
- zwischen Teilimplementierungen eines offenen Systems
- Portabilität
- von Anwendungen, die in offenen Systeme laufen
ISO/OSI-Referenzmodell
Namensgebung:
- ISO = International Standard Organisation
- OSI = Open Systems Interconnection
- Identifikation der beteiligten Ebenen
- Standardisierte Namensgebung
- Festlegung der Arbeit in den einzelnen Ebenen
- Vermittelt gutes Verständnis für Computernetze
Kommunikation in offenen Systemen ist erlaubt.
ISO/OSI-Referenzmodell - Schichten:
Anwendungsschicht:
Die Anwendungsschicht (Application Layer) unterstützt die
Endanwendungen durch Dienste bei der selbständigen
Kommunikation, wie z.B.
Dateitransfer, Datenbankzugriffe und E-Mail. Sie behandelt
weiterhin den allgemeinen Netzwerkzugang, Flusskontrolle und die
Fehlerbehebung.
Darstellungsschicht:
Die Darstellungsschicht (Presentation Layer) bestimmt das
Datenformat, mit dem der Informationsaustausch im Netzwerk erfolgt.
Sie trägt damit die Verantwortung für die
Protokollumwandlung, Datenverschlüsselung und die Wandlung von
Zeichensätze.
Steuerungsschicht:
Die Steuerungsschicht (Session Layer) ermöglicht die
Herstellung einer Verbindung zweier Anwendungen auf verschiedenen
Rechnern. Diese Schicht erkennt die Namen von Ressourcen (Computer,
Drucker usw.) im Netzwerk,
um diese ansprechen zu können. Außerdem synchronisiert
sie den Datenfluss.
Transportschicht:
Die Transportschicht (Transport Layer) sorgt für eine
fehlerfreie Übertragung der Datenpakete in der richtigen
Reihenfolge. Hier wird die Nachricht auf die richtige
Paketgröße angepasst.
Vermittlungsschicht:
Die Vermittlungsschicht (Network Layer) adressiert die Datenpakete,
damit diese zum richtigen Empfänger gelangen. Weiterhin wird
festgelegt, auf welchem Übertragungsweg die Pakete zum
Empfänger gesendet werden.
Sicherungsschicht:
Die Sicherungsschicht (Data Link Layer) nimmt die Datenrahmen von
der Vermittlungsschicht, wandelt diese in die physikalischen
Rohbits um und übergibt sie an die
Bitübertragungsschicht.
Bitübertragungsschicht:
Die Bitübertragungsschicht (Physical Layer) überträgt die
Rohbits auf das physikalische Übertragungsmedium. Diese
Schicht definiert die Eigenschaften des Netzwerks, wie
z.B. Netzwerkkarte,
Übertragungsmedium und Steckertyp.
Client/Server
Client/Server-Modell:
Vorzüge (gegenüber einer monolithischen/nicht-verteilten Architektur):
- Ressourcen-Sharing
Teure Ressourcen können einer großen Anzahl von Benutzern auch über größere Distanzen hinweg angeboten werden. - Erhöhte Ausfallsicherheit
Durch Redundanz der Server (z.B. File-Replikation) kann die Zuverlässigkeit des Systems erhöht werden. - Kostenersparnisse
Kleinrechner haben ein besseres Preis/Leistungsverhältnis als Mainframes. - Skalierbarkeit
Wachsende Leistungsbedürfnisse können durch sukzessives Hinzufügen einzelner Server befriedigt werden (statt Totalersatz der zentralen Lösung).
Diese "Versprechen" lassen sich jedoch nicht immer einlösen: oft anfälliger, aufwendigere Verwaltung, kritische Server und das Netzwerk als Engpass.
Client und Server:
- Client fordert Dienst beim Server an und wartet auf Antwort
- Server stellt Dienst bereit und antwortet
Verteilte Applikationen
Gründe:
- Aufgaben, die von Natur aus verteilt sind (Räumliche, geographische Trennung)
- Hohe Robustheit (Redundante Daten, Stand-By-Rechner)
- Wiederverwendung von Codeteilen (Nutzung von Diensten im Netz)
- Wirtschaftliche Gründe
Probleme:
- Erhöhte Komplexität viele verschiedene kommunizierende Prozesse sind schwer kontrollierbar und teilweise auch schwer verständlich
- Neue Fehlerklassen (Übertragungsfehler, Rechnerausfälle im Netz)
- Nebenläufigkeit (unabhängige Prozesse greifen auf dieselbe Ressource zu und überschreiben einzelne Werte, "Parallelitätsanomalie")
- Performance und Skalierbarkeit (Prozesse müssen auch verteilt effektiv und effizient sein)
- Fehlende unterstützende Software (z.B. wenig Unterstützung bei basalen Kommunikationstechnologien, z.B. Sockets)
Verteilungstransparenz:
Für den Benutzer/Entwickler steht ein verteiltes System wie ein zentrales System da.
Aufgliederung der Verteilungstransparenz:
- Zugriffstransparenz (Zugriff wie auf ein Zentralsystem)
- Lokationstransparenz (Ort der Ressource ist unbekannt, könnte während des Zugriffs auch migrieren)
- Replikationstransparenz (mehrere Kopien einer Ressource können gleichzeitig bestehen)
- Fehlertransparenz (Fehler wird vom Benutzer unbemerkt behoben, z.B. Faxgerät)
- Skalierungstransparenz (Wachstum des Gesamtsystems ist ohne Änderung der Applikationen möglich)
![]()
Middleware
Kommunikationsparadigmen
Neben der rasanten Entwicklung der Netzwerktechnologie haben sich Kommunikationsparadigmen entwickelt, die dem Entwickler eine sogenannte Kommuniktaionsmidelware zur Verfügung stellt.
Man unterscheidet einerseits- kommunikationsbasierende und nachrichtenbasierende Methoden,
- synchron und asynchron.
In der Reihenfolge zunehmender Verteilungstransparenz:
- Kommunikation über Sockets
- Nachrichtenbasierte Kommunikation
- Prozedurenaufruf
- Methodenfernaufruf
- Sprachunabhängiger Methodenfernaufruf
Kommunikation über Sockets
- Socket ist eine Software-Struktur, die in einer Netzwerkeinrichtung wie ein Kommunikations-Endpunkt arbeitet.
- Ein Socket setzt sich aus einer Netzwerknummer, einer Rechnernummer und einer Port-Nummer zusammen.
- Das Socket-Interface ist das am weitesten verbreitete LAN-Interface.
- Sockets sind die Basis für Berkeleys TCP/IP-Implementationen.
- Über diese Programmier-Schnittstelle (API) können Applikationen verteilt über das Netz programmiert werden.
Die drei Phasen der Socket-Kommunikation:
- Initialisierungsphase
Verbindung der Kommunikationsendpunkte- TCP: unterschiedliche Initialisierung von Server- und Client-Sockets
- Unabhängig von Rechnerstandort
- Lese- und Schreibphase
Symmetrische Kommunikation (write und read / send receive) - Aufräumphase
Freigabe der Ressourcen (symmetrisch)
Elementare Funktionen des Sockets für TCP/IP:
- Socket: Erzeugt Kommunikationsendpunkt
- Bind: Ordnet Socket lokale Adresse zu
- Listen: Ankündigung zur Bereitschaft zum Akzeptieren einer Verbindung
- Accept: Blockiert Aufrufer
- Connect: Versucht eine aktive Verbindung einzurichten
- Send: Sendet Daten über die Verbindung
- Receive: Empfängt Daten
- Close: Gibt Verbindung frei
Hinweis: Verbindungsorientiertes Kommunikationsmuster!
Probleme:
- Falsche Abstraktionsebene (nur einfache elementare Funktionen zum Senden und Empfangen)
- Sockets sind ausgelegt unter Verwendung allgemeiner Protokollstapel über Netzwerke zu kommunizieren
Nachrichtenbasierte Kommunikation
Warteschlangensysteme oder MOM (Message Oriented Middleware):
- Abstraktionsschicht oberhalb der Sockets
- Austausch von Nachrichten
- Verbindungsloser, Paketorientierter Kommunikationsdienst
- Meist für länger andauernde Übertragungen
- Zwischenspeicherkapazitäten
- Einer oder mehrere Kommunikations-Server
- Sender und Empfänger können vollkommen unabhängig voneinander ausgeführt werden
- Garantie für die Übergabe der Nachricht an die Zielwarteschlange
- Nachrichten können beliebige Daten enthalten
- Angabe der korrekten Adresse notwendig
- Automatische Überprüfung des Ziel
Geschichtliches:
- Standard für elektronische Post, angelehnt an das Modell der existierenden Briefpost
- X.400 wurde 1984 als Standard (vom CCITT) verabschiedet
- zweite (korrigierte) Version im Jahre 1988
- X.400(88) wurde im wesentlichen von ISO übernommen (MOTIS = Message Oriented Text Interchange System, ISO 10021)
Technischer Steckbrief:
- Store-and-forward: Meldungen werden asynchron übertragen und zwischengespeichert
- Strukturierte Meldungen (Briefkopf, Meldungsteile)
- spezielles Adressformat (Originator/Recipient-Namen)
Funktionales MHS-Modell
Das Message Handling System (MHS) hat zwei Sublayers:- Message User Agent (Protokoll zwischen Absender und Empfänger)
- Message Transfer (Protokoll zwischen Netzknoten des Store-and-forward-Netzes)
- dem MTS (Message Transfer System) entspricht die (gelbe) Post, ein MUA entspricht dem Briefkasten
- das MHS umfasst alle MUA und MTA.
MHS Meldungsformat:
gemäss den MHS-Sublayers hat eine MHS-Meldung zwei Teile:- Envelope (entspricht dem Briefumschlag) mit Adressangaben
- Content (entspricht dem Brief) mit Standardinformationen (Briefkopffelder für Von:, An:, Datum:, Betrifft:) und den Dokumenten selbst
MHS Adressformat:
- logisches Format für Empfängernamen (keine
Rechnernamen)
- das MHS muss selbst daraus die nötigen Adress- und Routing-Informationen ableiten.
- Name = Sammlung von Attributen (Originator/Recipient-Namen)
Auswahl möglicher Attribute und Beispiel:
c - country: ch
a - administration domain: 400net
p - private domain: vptt
o - organization: telecom
ou - organizational unit: -
s - surname (Familienname): Mustermann
g - given name (Vorname): Max
Schreibweise (z.B. Visitenkärtchen): C=ch, A=400net, P=vptt, O=telecom, S=mustermann, G=max
Vielzahl von (zum Teil optionalen) MHS-Diensten:
- normaler Transfer einer Meldung
- direkt an eine einzelne Adresse, oder an viele Empfänger
- als "Kopie-an"-Empfänger, oder "Geheime-Kopie-an"-Empfänger
- bestätigter Transfer
- der Empfang der Meldung wird durch das MTS bestätigt,
- kann die Meldung nicht ausgeliefert werden (Timeout), wird dies ebenfalls angezeigt
- verzögerter Transfer
- Meldung erst ab einem bestimmten Zeitpunkt ausliefern
- priorisierter Transfer
- Meldung mit einem "Wichtigkeitsvermerk" weiterleiten/ausliefern
- vertraulicher Transfer
- Meldung mit einem "Sensitivitätsvermerk" weiterleiten/ausliefern
SMTP - Simple Mail Transfer Protocol
Steckbrief:
- SMTP regelt den Meldungsaustausch zwischen zwei MTA
- beschrieben in RFC 821 (Meldungstransferprotokoll, 1982) und RFC 822
- (Meldungsformat, Vorgänger-RFC ab 1973)
- Grundprinzip: end-to-end-Transfer, d.h. möglichst kein Store-and-Forward
Zum SMTP-Protokoll:
- benutzt eine TCP/IP-Verbindung
- einfaches, text-basiertes Client/Server-Protokoll (ähnlich dem FTP-Befehlskanal)
Historische Lasten:
- verschiedene Mailformate
- 7-bit ASCII für Meldungsinhalt
- Längenbegrenzungen für Meldungen (64 kBytes)
SMTP Adress- und Mailformat:
Das Grundformat eines UA-Namen gemäss RFC 822 ist: mailbox@location
wobei:
- mailbox ist oft der login-name einer Person
- mailbox kann aber irgend ein Name innerhalb des Mailsystems der
location sein:
Aliasname(ad)fhtw-berlin.de - location muss nicht unbedingt eine Rechneradresse sein (Pseudodomain uucp)
Meldungsformat:
- ASCII-File, jede Zeile
ist mit
<CR><LF>abgeschlossen
Meldungsaufbau:
- Kopfteil (Header) mit Zeilen der Form Feld: Wert
- eine Leerzeile
- Meldungsinhalt (Body) beliebigen Formates
Mail Delivery Protocols:
Häufig sind der MUA (Mail User Agent) und der MTA (Mail Transfer Agent) nicht auf dem gleichen Computer installiert:
- spezielle Protokolle, um Meldungen via Netzwerk "auszuliefern": POP3, IMAP, DMSP, P7
- Meldungsversand erfolgt entweder mit einem separaten Protokoll (z.B. SMTP), oder ist ebenfalls im Delivery-Protokoll definiert.
E-Mail-Gateways:
Tatsache der heterogenen E-Mail-Welt:- um einen E-Mail-Standard herum entsteht eine E-Mail-Insel
- Gateways sollen solche Inseln (SMTP, X.400, CC-Mail, Compuserve, DecMail) untereinander verknüpfen
- Adress-Abbildung
- der Empfänger sollte immer ein Reply auf die Absenderadresse machen können
- benötigt großen administrativen Aufwand, um Abbildungsregeln international zu koordinieren
- Semantik-Unterschiede
- die SMTP-Welt kennt keinen "confirmed delivery"-Dienst
- MIME und X.400 haben unterschiedliche Bodytypes
- simpler ASCII-Text als kleinster gemeinsamer Nenner (falls Adressproblem lösbar)
E-Mail-Verteilerlisten:
E-Mail als "Groupware"- automatische Verteilerlisten mit eigener E-Mail-Adresse:
jede Meldung dorthin wird an mehrere Empfänger weitergesendet (mail exploder) - sehr nützlich für die (elektronische) Koordination innerhalb einer Arbeitsgruppe
- manuell: ein Verantwortlicher verwaltet ein File mit E-Mail-Adressen
- automatisch: Personen können sich selbst auf die Liste setzen (mittels E-Mail) und wieder von der Liste entfernen lassen
Dafür wird oft eine spezielle E-Mail-Adresse verwendet.
Beispiel:
- für An- und Abmeldung, Informationen
- für Meldungen zur Verteilung
unterschiedliche Regeln: freier Zugang (alles wird verteilt) oder moderiert (jede Meldung wird zuerst von einem Menschen begutachtet)
E-Mail-Probleme:
Mail-Authentizität und Konfidentialität
- Absenden unter falschem Namen ist einfach,
- Abhilfe in Zukunft durch digitale Unterschrift und Verschlüsselung (® PGP, X.509)
Mail-Schleifen, Mail-Storms
- bei store-and-forward Systemen müssen Vorkehrungen getroffen werden, damit E-Mails nicht endlos herumgereicht werden (Routing)
- Beispiele: Verteilerlisten mit gegenseitigen Einträgen, oder automatische E-Mail-Beantworter ("Ich bin in den Ferien")
- Abhilfe durch sorgfältiges Setzen der Absender-Adressen durch Mail-Exploder
Spamming, junk advertising
- d.h. "E-Mail-Verschmutzung" durch Kettenbriefe, Schnell-reich-werden-Aktionen
- die Adressen werden systematisch gesammelt (address brokers)
- wird als Teil von Werbekampagnen eingesetzt
- ist für die (menschlichen) E-Mail-Benutzer sehr lästig
- kann die persönlichen E-Mail-Adresse unbrauchbar machen.
- Nur begrenzte Hilfe durch intelligent UAs , Lösung als Teil einer Netz-Ethik.
EDI
EDI, EDIFACT und B2B:
EDI = Electronic Data Interchange; B2B = Business-to-Business- standardisierte Formate für den elektronischen Datenaustausch zwischen Unternehmen sind die Grundlage von Electronic Commerce (EC)
- Meldungen werden per E-Mail oder irgendeiner Art Filetransfer transportiert
- Dokumenten-Beispiele
Handel: Bestellung, Lieferschein, Transportauftrag, Rechnung
Bürodokumente: Brief, Vertrag (mit Unterschrift)
technische Daten: Baupläne (CAD) - Standardisierte EDI-Meldungen:
PAYORD=pay order message, CREADV=credit advice message - Branchenspezifische und national unterschiedliche
Substandards
z.B. Odette in der Auto-Industrie (Zulieferfirmen) - EDIFACT = Electronic Data Interchange for Administration, Commerce and Transport ist ein internationaler, branchenunabhängiger Standard
- United-States-Regierung verpflichtete sich (1993), EDIFACT zu benutzen
Vordefinierte Formate und Protokolle für elektronische Erfassung und Übertragung von Nachrichten
vereinbart in Trading Partner Agreements (TPA)
Einheit der Übermittlung: Interchange
- Header, Messages, Trailer
Nachrichtentypen: PRICAT, ORDERS, INVOIC
Konverter auf beiden Seiten: EDIFACT ⇔ inhouse format
Classic EDI- Probleme:
- schwierig für Menschen lesbar, Standardchaos
- teuer in Betrieb und Implementierung
- keine Einbindung von Binärdaten möglich
- aufwändige Anpassung bei geänderten Geschäftsprozessen
- umständliche Konvertierungsprozeduren
- problematische Weiterverarbeitung, Semantik nur implizit
Folge:
Entwicklung stagniert, Zurückhaltung der kleinen und mittleren Unternehmen
XML/EDI:
Vorteile:
- offen, preiswert
- Mensch-Maschine-Kommunikation wird unterstützt
- Geschäftsprozesse abbild- und optimierbar
- Einbindung von Binärdaten möglich
- Flexibilität durch freie Definition von Tags und Schemata
Nachteile:
- Sicherheit, Bandbreite
- mehr Übertragungsvolumen
- Flexibilität durch freie Definition von Tags und Schemata
Prozedurenfernaufruf - Remote Procedure Call (RPC)
Ein Wunschtraum?
- An Stelle des expliziten "Codieren" von Befehl und
Antwort-Meldungen:
Abbilden des Client/Server-Dialoges auf einen Prozedur- bzw. Funktionsaufruf (als Metapher) - Funktionsaufruf := Befehl an den Server
- Resultatwert := Antwort des Server
dabei: Übertragung beliebiger Datenstrukturen als Argumente/Parameter - Aus dem lokalen Prozeduraufruf wird ein Remote Procedure Call.
Probleme:
Semantische Unterschiede zwischen einem lokalen Aufruf und RPC:
- Namensraum:
bisher: Prozedurnamen müssen nur dem Compiler/Linker bekannt sein
RPC: Namen müssen netzweit publik gemacht werden - Speicherzugriff:
bisher: call-by-reference möglich ("globale" Variablen)
RPC: es steht nur call-by-value zur Verfügung - Darstellung von Daten:
bisher: Typendeklaration innerhalb des Programmes genügt
RPC: netzwerkweite Typendeklaration, eventuell zusätzliche Angaben zur Serialisierung - geänderte Fehlersemantik:
bisher: Fehler betreffen den lokalen Kontext des aufrufenden Programmes
RPC: neue Fehlerklassen (Netzprobleme, Speicherprobleme oder Crash des Server) - Ausführungsgeschwindigkeit
RPC hat seinen Preis (massiv höhere Latenz)
Aufgaben:
Sechs Schritte:
- Prozeduraufruf des Client, Parameter für die Übertragung serialisieren,
- Adresse des Server finden, Parameter übertragen,
- bei Empfang: Parameter in lokale Form bringen, Dienstprozedur aufrufen,
- nach Prozedurende: Ergebnis für die Übertragung serialisieren,
- Ergebnisse übertragen,
- empfangene Ergebnisse in lokale Form bringen und an Client zurückgeben.
Zwischen Schritt 1 und 6 ist der Client passiv (blockiert)
Ausführungssemantiken eines RPC:
Auch wenn innerhalb der Server-Prozedur kein Fehler auftaucht, kann der RPC-Aufruf wegen eines Server-Problemes (Crash) scheitern: Der Client kann nicht wissen, ob der Fehler vor, während oder nach Ausführung der Server-Prozedur eintrat.
Folgende Semantiken sind implementierbar (in den "Stub-Prozeduren"):
- "At least once"
nach einem Crash wird der Aufruf nochmals geschickt (und ausgeführt)
Einsatz für "idemtpotente" Nebeneffekte wie "Ventil schließen", Kontoabfrage - "At most once"
der Aufruf wird, falls überhaupt, höchstens einmal ausgeführt
Einsatz zum Beispiel für "x Aktien kaufen" - "Maybe"
es wird kein Aufwand für Fehlerbehebung getrieben
Tools für die RPC-Programmierung:
Drei Schritte für die RPC-Programmierung:
- Deklarationen
Datenstrukturen, Name der Server-Prozedur und ihrer Parameter - Client-Programm
Inklusive Stub (Serialisierung, Empfang/Versand, Fehlerbehebung) - Server-Programm
Inklusive Stub (Serialisierung, Empfang/Versand)
Unter Umständen beträchtlicher Implementierungsaufwand. Deshalb gewünscht:
- automatische Generation des Codes für die Serialisierung
- Bereitstellen der Sende/Empfang/Fehlerbehebungsroutinen für Client- und Server-Seite (RMI in Java)
Spezielle "Interface Description Language":
- XDR (External Data Representation)
- objektorientiert: IDL (Interface Description Language) von CORBA und COM
Methodenfernaufruf - Remote Method Invocation (RMI)
Vergleichbar mit RPC, jedoch werden hier Objekte verbindungsorientiert aufgerufen.
Objekte als gekapselte Daten (Status) mit den zu verwendenden Operationen (Methoden) - Bereitstellung über Schnittstellen
DCOM Distributed Component Object Model:
- Bei COM handelt es sich um eine Technologie, die es dem Entwickler Windows-basierter Programme ermöglicht, aus seiner Applikation heraus Funktionalitäten einer anderen Applikation zu benutzen und mit den Methoden und Eigenschaften der zur Verfügung gestellten Objekte, Daten abzufragen und zu ändern.
- Von Mircosoft 1993 entwickelt
- Löste DDE (Dynamic Data Exchange) als Basisdienst für OLE (Object Linking and Embedding) ab
- Basis für Active X und OLE2
- Instanzen der Objekt werden auf dem Server erzeugt (DLL)
- Komponenten-DLLs werden vom Client geladen und
- DLLs werden nicht mittels Namen, sondern mit dem Globally Unique Identifier (GUID) angefordert
- Zuordnung geschieht über Windows-Registry
- Verbindung mit dem Server ist nicht statisch
- COM-Schnittstellen sind binärkompatibel - Umgebungen C/C++, Java, Java-Skript, VisualBasic oder Delphi
Verwendung von COM-Objekten:
alle wesentlichen Funktionen von Saperion® werden über COM-Objekte zur Verfügung gestellt (archie32.tlb enthält die Saperion® Objektbibliothek)
- Innerhalb anderer Programme erfolgt die Steuerung von
Saperion® über individuelle Programmierung (Manipulation
der Saperion® COM-Objekte)
- Makros z.B. mit VBA in Microsoft Word, Microsoft Excel, Microsoft Access
- Einbindung in bestehende Programme (z.B. Visual Basic)
- Innerhalb von Saperion® erfolgt die Automatisierung über die Event Script Option. Die Makromodule werden in Enable Basic erstellt und können sowohl Saperion®-Objekte wie auch COM-Objekte anderer Applikationen nutzen.