Wirtschaftsinformatik (Bachelor-Studiengang): Rechnerarchitketur & Betriebssysteme (1. Semester)
Sie sind hier: Startseite › Wirtschaftsinformatik › Rechnerarchitektur/Betriebssysteme: CPU, RAM und Bus
BM / CM, Kurs vom 01.04.2002 - 30.09.2002
Idee der Programme
Wie sieht eine Programmsteuerung aus?
Es sollen zwei Variablen wahlweise mit and oder mit or verknüpft werden.
Idee:
- Aufteilung der Eingabe-Variablen in Datenvariablen und Steuervariablen
- Bereitstellung verschiedener festverdrahteter Funktionen (Schaltnetze)
- Steuerung des Datenflusses zu den gewünschten Funktionen
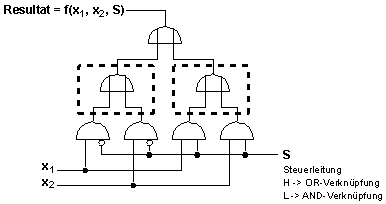
Bildbeschreibung "Programmsteuerung I": Schaltnetz.
Erklärung:
S ist Variable
S wird auf false gesetzt
=> x1, x2 geht durch erste Schaltung (und)
S wird auf true gesetzt =>
x1, x2 geht durch zweite Schaltung (oder)
Bildbeschreibung "Programmsteuerung I": Schaltnetz.
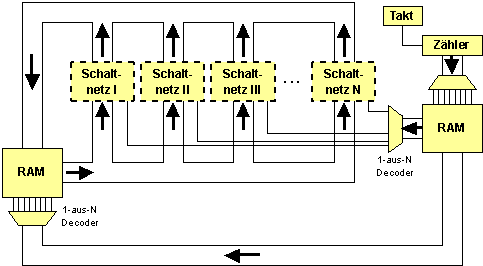
Ist das ein Computer?
Ja, das ist ein Computer, der aber ein paar Nachteile hat:- Es fehlt eine globale Taktsteuerung, die u.a. das Laden aus dem RAM, das Speichern in den RAM sowie das Erhöhen des Zählers koordiniert.
- Es sind keine "Sprünge", d.h. kein Setzen des Zählers möglich.
- Es sind nur monadische Operationen möglich (monadisch = nur 1 Operand, wie z.B. Negation)
- Das Ergebnis wird immer an die Stelle des Operanden geschrieben, d.h. dieser wird immer überschrieben.
· Unser Computer wird jetzt schrittweise weiter entwickelt
· Weil er so klein ist, soll er Maxi heißen
(lat. Nomen est omen = Name ist das Zeichen/Merkmal)
Computer "Maxi" mit Sprüngen:
Bildbeschreibung "Comuter Maxi mit Sprüngen": Schaltnetz.
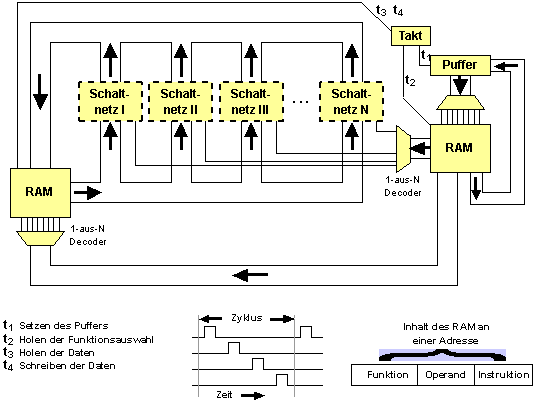
Takt
Takt = Zyklisches (sich wiederholendes) Pulssignal, das global oder für einen Teilbereich einen Arbeitsschritt veranlasst. Die Aufgabe des Taktes besteht in der Synchronisation verschiedener Bauteile.
Synchronisation = zeitliche Abstimmung
Wenn - wie bei Maxi - mehrere Takte für einen komplexen Arbeitsschritt (Ausführung einer Instruktion) erforderlich sind, wird von Phasen gesprochen. Maxi benötigt einen 4-Phasen-Takt, d.h. für eine Instruktion sind 4 Takte erforderlich.
Puffer (Latch)
Entkoppeln durch Puffer:
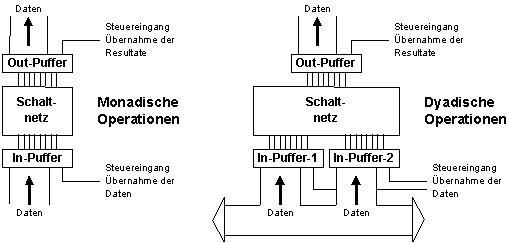
Bildbeschreibung "Entkoppeln durch Puffer": Schaltnetz. Monadische Operationen: Daten gelangen über einen Puffer in das Schaltnetz. Dyadische Operationen: Daten gelangen über mehrere Puffer in das Schaltnetz.
Entkoppeln durch Speicher:
Das zeitliche Entkoppeln zweier Bereiche bewirkt durch eine Trennung durch einen Speicher ein unabhängiges Arbeiten.
Das ist ein allgemeines Prinzip, das z.B. auch im Internet bei E-Mail angewendet wird.
Beispiel: Beim Telefonieren müssen beide Gesprächspartner gleichzeitig anwesend sein (Synchronität); durch Einführung eines Speichers (Anrufbeantworter) ist dies nicht mehr erforderlich: jeder ist viel unabhängiger von einander.
Puffer = Zwischenspeicher = Speicher zur zeitlichen Entkoppelung
Eine einfache Kette von Flip Flops realisiert einen Puffer, der auch Latch genannt wird.
Maxi mit Puffern:
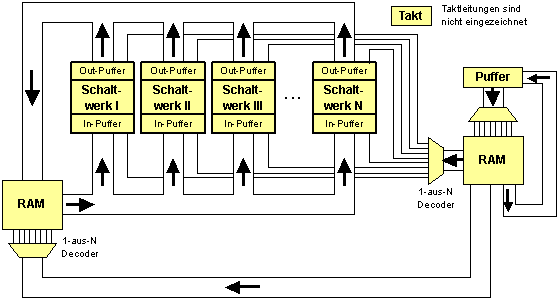
Bildbeschreibung "Maxi mit Puffern": Schaltnetz.
Jede adressierbare Bitkette aus RAM1 wird Instruktion (Befehl) genannt. RAM1 enthält die Instruktionen (Befehle) bzw. den Programmcode, kurz: Code.
Alle Puffer werden durchnumeriert, wobei die Nummer die Codierung in den Instruktionen bildet: Operationscode, kurz: Opcode genannt.
RAM2 enthält die Operanden (Daten).
Jede Instruktion enthält neben dem Opcode die Adresse eines Operanden. Daher heißen diese Befehle: 1-Adress-Befehle.
Der Puffer heißt Programmzähler (Program Counter).
Jede Instruktion enthält auch die Adresse der nächsten Instruktion, die in den Programmzähler während jeder Befehlsausführung geschrieben wird.
Phasen der CPU-Arbeit
Ausführungszyklus eines Interpreters (fetch decode execute cycle):
- Holen der nächsten Instruktion
- Decodieren der Instruktion
- Holen aller Operanden
- Ausführen der Instruktion
- Bestimmen der Adresse der nächsten Instruktion
- Weiter bei 1.
Interpreter = Programm oder Hardware, was die Semantik von Befehlen realisiert.
Semantik sind hier alle definierten Effekte (Wirkungen) von Befehlen.
Effekte könnten sein: Variable auf -3 setzen, zwei Zahlen addieren und das Ergebnis an eine bestimmte Stelle im Speicher schreiben.
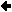
![]()
Von-Neumann-Architektur
Rechnertypen
Harvard-Architektur:
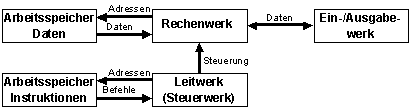
Bildbeschreibung "Harvard-Architektur": Es gibt einen Arbeitsspeicher für Daten und einen Arbeitsspeicher für Instruktionen.
Princeton-Architektur (von Neumann):
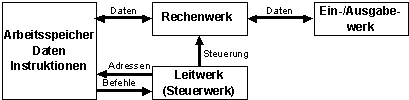
Bildbeschreibung "Princeton-Architektur": Es gibt nur einen gemeinsamen Arbeitsspeicher für Daten und Instruktionen.
Maxi als Harvard-Rechner:
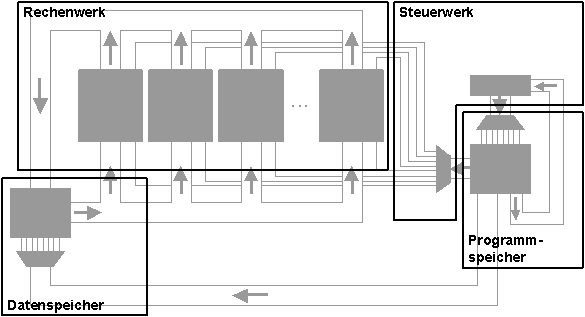
Bildbeschreibung "Maxi als Harvard-Rechner": Aufteilung des Schaltnetzes in die Bereiche Rechenwerk, Steuerwerk, Datenspeicher und Programmspeicher.
Princeton-Architektur (von Neumann)
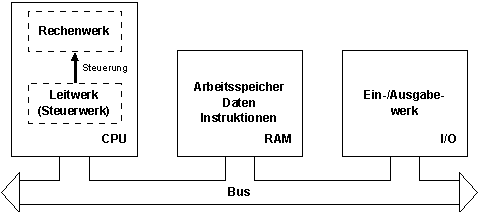
Bildbeschreibung "Princeton-Architektur": Bidirektionaler Bus mit CPU (Rechenwerk und Steuerwerk), RAM (Arbeitsspeicher Daten und Instruktionen) und I/O (Ein-/Ausgabewerk).
Der RAM mit den Instruktionen wird mit dem RAM der Daten zusammengelegt, was zu längeren Adressen oder zur Verkleinerung des Speichers für den Programmcode führt.
Der "untere" Bus zum Laden der In-Puffer wird mit dem "oberen" Bus zum Speichern in den Daten-RAM zusammengelegt; damit wird dieses Bus bidirektional (abwechselnd in beiden Richtungen) betrieben.
Eigenschaften:
- CPU (Central Processing Unit) besteht aus Rechenwerk und Leitwerk als Einheit
- Bus = Universeller bidirektionaler Kommunikationsweg für alle Befehle und Daten
- Arbeitsspeicher (RAM) enthält Code und Daten.
- Ein-/Ausgabewerk besteht aus verschiedenen Schnittstellen zu (externen) peripheren Geräten
- Vorteile:
- Universell und flexibel
- Minimalität der Hardware, optimale Nutzung
- Nachteile:
- Bus als zentraler Kommunikationsweg ist Nadelöhr
Viele Rechner, insbesondere PC haben nicht die reine von-Neumann-Architektur.
Modell der CPU und I/O-Geräte:
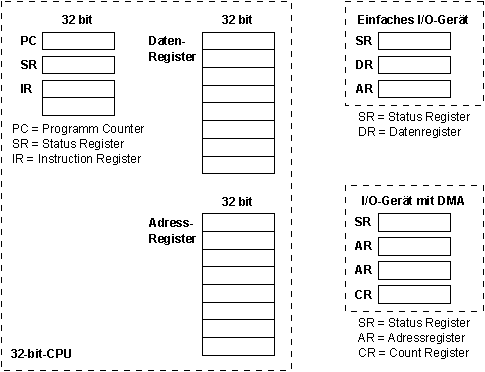
Bildbeschreibung "Modell der CPU und I/O-Geräte": Eine 32-bit-CPU besteht aus einem 32-bit-Datenregister (kurz: DR) sowie einem 32-bit-Adressregister (kurz: AR), einem Programm Counter (PC), einem Status Register (kurz: SR) und einem Instruction Register (kurz: IR). Ein einfaches I/O-Gerät besteht aus SR, DR und AR; ein I/O-Gerät mit DMA aus SR, zwei AR und CR (Count Register).
Register
Register = Schneller Speicher innerhalb der CPU, der durch das Programm direkt ansprechbar ist.
Register der CPU:
- Program Counter (PC) enthält die Adresse der nächsten Instruktion
- Status Register (SR) enthält Resultate der letzten Instruktion sowie globale Zustände, wie z.B. Previlegien
- Instruction Register (IR) enthält die gerade auszuführende Instruktion (nicht per Software ansprechbar)
- Datenregister als universell verwendbares Register für Zwischenergebnisse
- Adressregister als Register für Adressen in den Arbeitsspeicher, teilweise mit reservierter Bedeutung
Register der I/O-Geräte:
Diese Register können über den Bus direkt von der CPU gelesen und verändert werden.
- Status Register (SR) zeigt den Zustand des I/O-Vorgangs an, Schnittstelle zum Starten und Stoppen eines I/O-Vorgangs
- Datenregister (DR) enthält nach Einlese-Operation das eingelesene Datum zum Abholen für die CPU bzw. vor Schreiboperation das zu schreibende Datum für das Gerät
- Adressregister (auch mehrere) enthalten die Adresse im RAM oder auf dem I/O-Gerät
- Count Register (CR) enthält die Länge des Datenblocks, der während der I/O-Operation behandelt wird
Modell des RAM und des I/O-Bereichs:
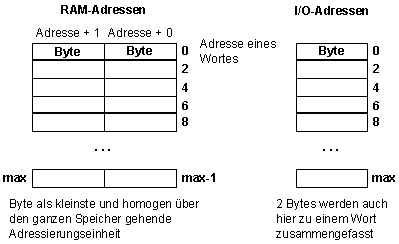
I/O-Adressen werden manchmal Ports bzw. Port-Nummern genannt.
I/O-Adressen können getrennt vom RAM, aber auch im selben Adressbereich sein.
Schichtenmodell
- Komponenten: Komplexe aus Bausteinen wie CPU, RAM, I/O-Bausteine
- Bausteine: Gatter-Komplexe wie Register, Addierer, 1-aus-N-Decoder, Puffer
- Gatter: Gatter wie nand, nor, Taktgenerator, Monoflops, auch Verstärker, Schnittstellen
- Physik: Technologien, z.B. DTL, TTL
Monoflops sind Flip Flops, die nur für eine bestimmte Zeit in einem Zustand verharren und dann automatisch in den stabilen anderen Zustand übergehen.
Schnittstellen sind hier Gatter mit Tri-State-Ausgängen, also Ausgängen mit drei Zuständen (H, L sowie "entkoppelt").
![]()
Bus
Prinzipien von Bussystemen
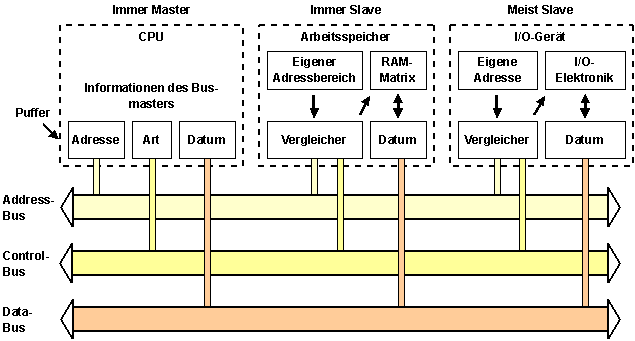
Bildbeschreibung "Prinzipien von Bussystemen": CPU, Arbeitsspeicher und I/O-Gerät greifen auf die drei Busse (Adress-, Kontroll-, Datenbus) zu.
Adressbus: Datenleitungen mit den Adressen der Kommunikationspartner (8 bis 32 Leitungen):
- Arbeitsspeicher/RAM: Adressen sind die der RAM-Zellen (Bytes, Wörter, Doppelwörter)
- Adressen von Schnittstellen zur peripheren Geräten: Ports
- Wird eine Adresse generiert, die zu keinem Partner gehört, gibt es keine Kommunikation
Datenbus: Datenleitungen mit den zu transportierenden Daten (8 bis 64 Leitungen)
Kontrollbus: Leitungen, die der Steuerung dienen
Aufgaben des Kontrollbusses:
- Art der Zugriffs:
- Auf Arbeitsspeicher/RAM
- Auf I/O-Gerät
- Zuteilung des Busses an ein Partner, der dann Master wird: Der Master belegt den Bus und bestimmt Adressen sowie Kommunikationsrichtung. Die vom Master angesprochenen Partner sindSlaves, alle anderen sind unbeteiligt.
- Mitteilung des Wunsches, Master zu werden.
- Mitteilung von Unterbrechungen und Reset-Signale.
- Synchronisation zwischen den Partnern. Anzeige, wann die Signale einen stabilen Pegel haben, Takt, Bestätigungen, Flusskontrolle
Master
Wer kann alles Master werden?
- Alle CPU - es können mehrere vorhanden sein.
- I/O-Geräte mit der Fähigkeit zum Zugriff auf den Arbeitsspeicher (DMA).
Wie lange bleibt ein Master Master?
- Bis er freiwillig den Bus abgibt.
- Bis der Bus ihm die Kontrolle wieder abnimmt.
Wie wird ein Partner Master?
- Eine spezielle Elektronik (Arbiter = Entscheider) teilt den Bus den Partnern zu, wobei gleich berechtigte Prioritäten realisiert werden können, oder:
- Jeder meldet den Wunsch an und der setzt sich durch, der am nächsten zur CPU im Bus sich befindet (Daisy Chaining)
Arten von Bussen
Bei den Bussen wird unterschieden, ob sie zur Kommunikation zwischen CPU und anderen Komponenten dienen (Systembusse) oder zwischen I/O-Schnittstellen und peripheren Geräten (I/O-Busse).
Es gibt viele Systembusse, verbreitet sind:
- ISA (Industry Standard Architecture, 1985)
- EISA (Extended Industry Standard Architecture)
- PCI (Peripheral Component Interconnect)
- MCA (Micro Channel Architecture, 1987)
- VESA (Video Electronics Standards Association): VL-Bus
Die I/O-Busse sind auch vielfältig, verbreitet sind:
- SCSI (Small Computer System Interface)
- Firewire
- USB (Universal Serial Bus)
| XT | ISA | MCA | EISA | VL | PCI | |
|---|---|---|---|---|---|---|
| Datenleitungen | 8 | 16 | 32 | 32 | 32/64 | 32/64 |
| Adressleitungen | 20 | 24 | 32 | 32 | 32 | 32 |
| DMA-Geschwindigkeit [MB/s] | 2 | 2 | 20-33 | 20-33 | 75/150 | 130/260 |
| Bus-Takt [MHz] | 4,7 | 8 | 10 | 8,33 | 25-50 | 33 |
Zugriff auf Geräte-Register
Spezielle I/O-Instruktionen:
Die I/O-Register haben spezielle Adressen (Port-Nummern) z.B. Intel x86.
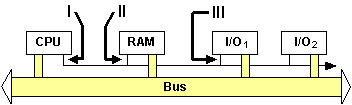
Bildbeschreibung "Spezielle I/O-Instruktionen": CPU, RAM und zwei I/O greifen auf den Bus zu.
- CPU setzt bei I/O-Instruktionen eine spezielle Leitung des Kontrollbusses
- RAM ignoriert Bus, wenn diese Leitung gesetzt ist
- I/O ignoriert Bus, wenn diese Leitung nicht gesetzt ist
Memory Mapped I/O:
Adressen der I/O-Register befinden sich innerhalb des Bus-Adressraums. Zugriff mit normalen Instruktionen, es gibt keine I/O-Instruktionen.
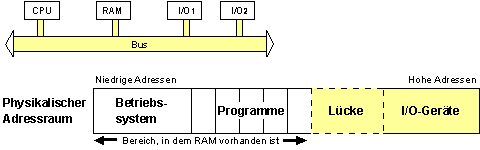
Bildbeschreibung "Memory Mapped I/O": Die niedrigen Adressen des physikalischen Adressraumes werden vom Betriebssystem und Programmen belegt, die hohen von den I/O-Geräten.
I/O-Geräte verhalten sich wie der RAM.
CPU kommuniziert mit I/O-Geräten wie mit dem RAM.
Direct Memory Access(DMA)
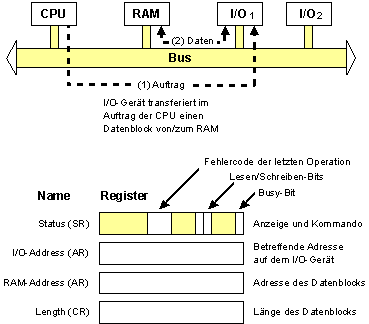
Bildbeschreibung "Direct Memory Access": I/O-Gerät transferiert im Auftrag der CPU einen Datenblock vom/zum RAM.
![]()
RAM und ROM
Arten von Halbleiterspeichern:
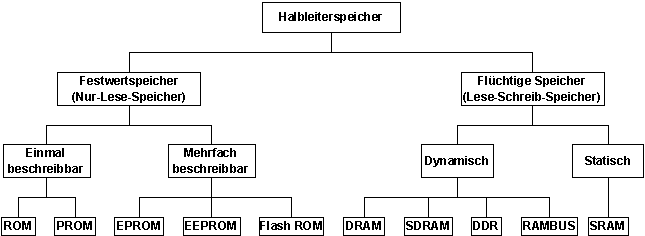
Bildbeschreibung "Halbleiterspeicher": Obergruppen bilden die Festwertspeicher (Nur-Lese-Speicher) und die Flüchtigen Speicher (Lese-Schreib-Speicher). Die Festwertspeicher sind unterteilbar in einmal beschreibbar (ROM, PROM) und mehrfach beschreibbar (EPROM, EEPROM, Flash ROM). Die Flüchtigen Speicher sind unterteilbar in dynamisch (DRAM, SDRAM, DDR, RAMBUS) und statisch (SRAM).
Static Random Access Memory (SRAM):
Speichereinheiten sind Flip Flops. Durch geschickte Reduktion auf wenige Transistoren wird trotzdem eine hohe Integrationsdichte erreicht.
- Schnell: Zugriffszeit 6 ... 100 ns
- Teuer
- Größe: Relativ klein
Dynamic Random Access Memory (DRAM)
Speichereinheiten sind Kondensatoren, die regelmäßig wieder geladen werden und deren Inhalt beim Auslesen zerstört und deshalb wieder hergestellt wird (refresh).
- Langsam: Zugriffszeit >50 ns
- Billig
- Größe: Groß
(Platz auf Chip um min. Faktor 4 kleiner als bei SRAM)
DRAM haben eine komplexe chipinterne Steuerung, wobei diese sowie die Zusammenstellung mehrerer Chips die Leistungsfähigkeit beeinflusst. Die einzelnen Arten unterscheiden sich in der Steuerung.
Bei DRAM muss zwischen der
- Zugriffszeit (Zeit bis zum Abliefern des Inhalts nach Anforderung) und der
- Zykluszeit (Zeit bis zur erneuten Bereitschaft nach Anforderung)
Arten von DRAM:
- Normaler DRAM (FPM = Fast Page Mode)
Der CPU-Takt arbeitet asynchron (zeitlich nicht gekoppelt) zur Steuerung des RAM. Intern werden ganze Zeilen der Speichermatrix (Page) ausgelesen und zwischengepuffert. Wenn die nachfolgende Anforderung sich auf diese Seite (Page) bezieht, kann sofort der Wert ausgegeben werden. - EDO-DRAM
(Hyper-Page-Mode,Extended Data Output)
Um bis zu 30% kürzere Zugriffszeit gegenüber DRAM (FPM) aufgrund innerer Verschaltung. Der zeitliche Abstand zwischen Anforderungen ist kürzer: Zugriffszeiten bei 50-60 ns. - Synchronous Dynamic Random Access Memory (SDRAM)
SDRAM arbeiten mit dem Systemtakt (66 MHz und 100 MHz) und haben Zugriffszeiten im Bereich von 8-15 ns.
Varianten von SDRAM:- Ein EEPROM (Festwertspeicher) gibt Auskunft über das zeitliche Verhalten
- Ohne EEPROM muss im Betriebssystem (BIOS) die Angaben über das zeitliche Verhalten vorhanden sein
- SDRAM II,
DDR-DRAM
(Double Data Rate)
SDRAM mit doppelter Datenrate bei der Ausgabe beim Auslesen.
Trotz aller Tricks wird die Geschwindigkeit des RAM durch die Geschwindigkeit der Speicherzellen bestimmt. Diese ist in den letzten Jahren nur wenig gesteigert worden.
- RAMbus DRAM
Bis zu 32 (normaler) DRAM-Chips bilden einen Bus mit einer Datenbreite von 16 bit. Durch die interne Verschränkung und weiterer Tricks werden höhere Datenraten erreicht.
Die DRAM samt Controller liegen auf einem RIMM (Rambus Inline Memory Module) mit 184 Anschlüssen. RIMM gibt es in den Größen 64, 128 und 256 MB.
RAMbus- und DDR-RAM sind z. Z. die beiden Mitbewerber auf dem Speichermarkt mit jeweils den höchsten Leistungsansprüchen.
- Dual-Port-RAM
RAM, der in der Lage ist, gleichzeitig einen Bereich zu lesen und zu beschreiben - VRAM (Video Random Access Memory)
VRAM sind Dual-Port-RAM, die als Zwischenspeicher zwischen der CPU und dem Videocontroller (der Hardware zur Ansteuerung des Monitors) dienen
VRAM haben darüber hinaus noch die Möglichkeit, auf einfache Weise eine nebeneinander liegende Reihe von Zellen sequenziell schnell auszulesen, was für die Bildschirmansteuerung wichtig ist.
Die Technik des VRAM sorgt dafür, dass die Bildschirme trotz/wegen der hohen Bildwiederholfrequenz nicht flimmern.
- Variante: SGRAM = Synchronous Graphic Random Access Memory
Speichermodule
Mehrere RAM-Chips samt Controller werden auf kleinen Karten (PCB = Printed Circuit Board) montiert, die Speichermodule (auch "Riegel") genannt werden.
Diese Module werden in Steckplätzen auf der Hauptplatine gesteckt, die dann den Arbeitsspeicher ausmachen.
Es gibt die Möglichkeit der automatischen Fehlererkennung und Korrektur (ECC = Error Correction Code = Fehlerkorrekturcode).
- Vorteile:
- Hohe Flexibilität
- Leichter Ein-/Ausbau
- Nachteile:
- Geringere Geschwindigkeit aufgrund längerer Leitungen
- Geringere Geschwindigkeit aufgrund Steckplatz
Single In-line Memory Module (SIMM):
- 30poliges SIMM-Modul unterstützt 8 Datenbit
- 72poliges SIMM-Modul unterstützt 32 Datenbit
Double In-line Memory Module (DIMM):
- 168polig (168 Anschlüsse) mit einem Datenpfad von 64 bit
- Vorwiegend SDRAM, aber auch EDO-DRAM
- Sondernform: Small Outline Double In-line Memory Module (SO DIMM) für Laptops
ROM
- 1x beschreibbar:
- ROM = Read Only Memory:
Speicherinhalt wird bei der Herstellung des Chips gleich (mit der Maske) gesetzt.
Lohnt sich nur in großen Stückzahlen - PROM = Programmable Read Only Memory:
Speicherinhalt wird einmal elektrisch geschrieben (programmiert) und kann anschließend nicht mehr geändert werden
- ROM = Read Only Memory:
- Mehrfach beschreibbar:
- EPROM =
Electrical Programmable Read Only Memory:
Speicherinhalt kann durch starkes UV-Licht gelöscht und elektrisch gesetzt (programmiert) werden.
Chips haben ein Quarzfenster zum Löschen, das während des Gebrauchs abgedeckt sein sollte.
Offenes Fenster: Neonlicht löscht innerhalb 3 Jahren, Sonnenlicht innerhalb einer Woche.
- EPROM =
Electrical Programmable Read Only Memory:
EPROM: Brennzeit für 128 KB: 2-20 Min.
- Löschzeit: 15-20 Min.
- Zugriffszeit: 200 ... 450 ns
EEPROM: Elektrisch löschbare und programmierbarer ROM.
- Löschen erfolgt Blockweise
Flash-ROM: Variante des EEPROM.
- Löschen erfolgt vollständig in einem Stück oder seitenweise (ca. 1 s)
- min. 10.000 Lösch- und Programmierzyklen
- Einsatz u.a. bei digitalen Kameras
- Typische Größe: 1 Mbit (128 KB)
- Zugriffzeit ca. 120 ns
![]()
Cache
Cache ist ein schneller Zwischenspeicher, in dem Daten bzw. Instruktionen gehalten werden, von denen gehofft wird, dass auf diese bald zugegriffen wird.
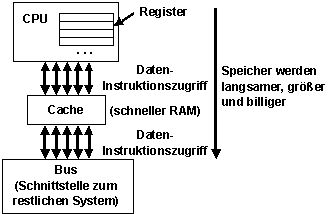
Bildbeschreibung "Cache": Zwischenspeicher zwischen CPU und Bus.
Mechanismus:
- CPU stellt Leseanfrage
- Cache prüft, ob Datum
vorhanden
- Falls ja, Datum wird unmittelbar geliefert (cache hit)
- Falls nein, Datum wird aus RAM geladen, in den Cache gebracht und der CPU geliefert (cache miss)
- CPU schreibt ein Datum
- Datum wird vom Cache
übernommen und
- unmittelbar in den RAM geschrieben (write-through) oder
- erst dann in den RAM geschrieben, wenn dieses Datum verdrängt wird (write-back).
Cache Level
In Abhängigkeit vom Ort, Technologie und Funktion werden verschiedene Levels (Ebenen) eingeführt:
- Level 1 (L1) Cache: Cache innerhalb des CPU-Chip
- Level 2 (L2) Cache: Cache zwischen CPU und Bus
Neuere (komplexere) Architekturen haben drei Level:
- Level 1 (L1) Cache: Cache innerhalb des CPU-Chip
- Level 2 (L2) Cache: 2. Cache auf CPU-Module (in unmittelbarer Nähe der CPU)
- Level 3 (L3) Cache zwischen CPU und Bus
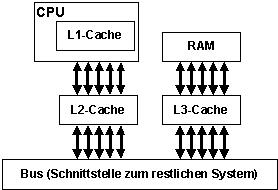
Bildbeschreibung "Cache Level": Der L1-Cache befindet sich in der CPU, der L2-Cache zwischen CPU und Bus, der L3-Cache zwischen RAM und Bus.
Cache-Strategien
- LRU = Last Recently Used:
Es werden die Daten zuerst entfernt, deren letzte Benutzung am längsten zurückliegt. Gut für lokale Bereiche, z.B. eine Schleife, die sich vollständig im Cache befindet. - LFU = Least Frequently Used:
Es werden die Daten, auf die am wenigsten zugegriffen wurde, verdrängt. - FIFO = First In First Out:
Verdränge die Daten, die am längsten - unabhängig von der Benutzung - im Cache sind.
Probleme der Cache Realisierung
Cache-Kohärenz (Übereinstimmung mit RAM):
Der Cache muss immer die "wahren", tatsächlichen Daten enthalten, auf keinem Fall veraltete. Dieses Problem tritt bei Mehr-Prozessoranlagen sowie bei I/O auf. In diesen Fällen schreibt Hardware unter Umgehung des Cache etwas in den RAM.
Umgekehrt muss auch der RAM die wahren Daten haben, z.B. wenn der Cache die aktuellen hat. Auch dies betrifft andere Prozessoren und I/O.
Trashing:
Trashing ist ein Effekt, bei dem die Daten, die als nächstes benötigt werden vor diesem Zugriff aus dem Cache entfernt werden, so dass der Cache wenig Effekt hat.
Speicherhierarchie:
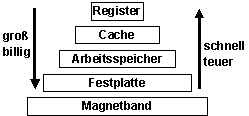
Bildbeschreibung "Speicherhierarchie": Von schnell und teuer bis groß und billig: Register, Cache, Arbeitsspeicher, Festplatte, Magnetband.
Ziele der Technik:
Durch Software - basierend auf korrekten Modellen der Speicherbenutzung - werden die Daten auf der Hierarchie zum richtigen Zeitpunkt nach oben bzw. nach unten kopiert.
An der Spitze werden die Daten verarbeitet und befinden sich in flüchtigen Speichern, an der Basis werden die Daten langfristig aufbewahrt und zur späteren Bearbeitung vorbereitet.
![]()
Motherboards
Motherboard = Mutterplatine = Platine/Karte mit CPU, RAM, Bus und optional den Schnittstellen zur Ein-/Ausgabe.
Das Motherboard hat eine viel niedrigere Taktrate als die CPU:
- 66 MHz (veraltet)
- 100 MHz (üblich)
- 133 MHz (neu)
Dies Werte gelten für den Front Side Bus (FSB), auf den die RAM abgestimmt sind: PC66, PC100, PC133 (z.B.).
Es gibt entsprechend der Leistung abgestufte Busse:
- Front Side Bus (FSB): CPU mit dem Chip-Satz
- Speicherbus
- I/O-Busse
Der Chipsatz steuert die einzelnen Komponenten. Dessen Leistungsfähigkeit hat einen erheblichen Einfluss auf die gesamte Performance des Rechners.
Es gibt viele verschiedenen Chip-Sätze, die mit bestimmten Entwürfen der Motherboards zusammengehen. Motherboards mit wenigen festen Komponenten und vielen Bus-Steckplätzen werden modular genannt.
PC-Busse auf Motherboards:
- ISA (Industry Standard Architecture, 1985): Alt bis veraltet
- EISA (Extended Industry Standard Architecture): Alt bis veraltet
- PCI (Peripheral Component Interconnect): Aktuell
Peripheral Component Interconnect (PCI):
- Version 2 von 1994, Version 2.1 hat doppelte Taktrate
- 32 bit Daten- und Adreßbus
Parity für Daten und Adressen - Synchrone Bus-Operationen bis 33 MHz
- Selbstkonfiguration aufgrund von Komponenten
- Plug-and-Play fähig
- Prozessor-unabhängig
Wird u.a. auch von Apple Macintosh (PowerPC) benutzt - Heute in PC üblich.
Verfahren zur Beschleunigung:
Cache (Idee): Geschickte Benutzung schneller Pufferspeicher mit automatischer Steuerung
Pipelining (Idee): Versuch so viele Phasen der Befehlsausführung wie möglich trotz sequenzieller Programme parallel auszuführen.
Pipelining:
Verfahren, bei dem Phasen der Instruktionsausführung verschiedener hintereinander auszuführender Befehle parallel ausgeführt werden, ohne dass Phasen gleicher Art parallel ablaufen.
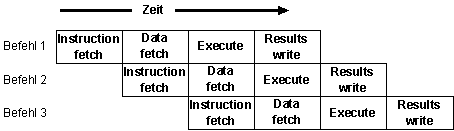
Bildbeschreibung "Pipelining": Drei Befehle werden versetzt ausgeführt. Ist Phase 1 in Befehl 1 ausgeführt, dann startet Befehl 2 mit Phase 1. Wenn auch diese Phase beendet ist, dann startet Befehl 3 mit Phase 2. Dies zieht sich durch die Phasen 1 bis 4 (Instruction fetch, Data fetch, Execute, Results write).
Superpipelining:
Pipelining-Verfahren, bei dem auch Phasen gleicher Art (teil-)parallel ablaufen.
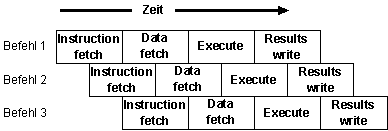
Bildbeschreibung "Superpipelining": Drei Befehle werden versetzt ausgeführt. Ist Phase 1 in Befehl 1 teilweise ausgeführt, dann startet Befehl 2 mit Phase 1. Wenn auch diese Phase teilweise beendet ist, dann startet Befehl 3 mit Phase 2. Dies zieht sich durch die Phasen 1 bis 4 (Instruction fetch, Data fetch, Execute, Results write).
Super Skalar Pipelining:
Pipelining-Verfahren, bei dem mehrere Instruktionen (teil-)parallel ablaufen.
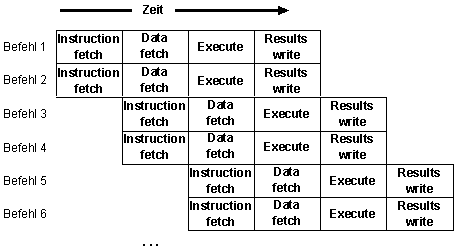
Bildbeschreibung "Super Skalar Pipelining": Sechs Befehle werden ausgeführt. Während jeweils zwei Befehle gleichzeitig in ihren Phasen ausgeführt werden, starten die restlichen Befehle (jeweils in Zweier-Paaren) wieder Phasen-versetzt.
Phasen einer Befehlsausführung:
- Instruction fetch
- Data fetch
- Execute
- Results write
Typen von CPU-Architekturen:
CISC = Complex Instruction Set Computer; typische Vertreter: M68000, Intel x86
RISC = Reduced Instruction Set Computer. Versuch in den 80er Jahre, durch
- Vereinfachung der Instruktionscodierung,
- Reduktion des Funktionsumfangs (Anzahl der Instruktionen) und
- Aufteilung in Datentransport- (Load/Store) und Verarbeitungsinstruktionen
Platz auf dem Chip zu erhalten, um einen größeren Cache zu benutzen.
Inzwischen sind RISC-CPU genauso komplex wie CISC:
der Unterschied
ist verschwommen.
Typische Vertreter: PowerPC, Alpha, SPARC